Hvis du er udvikler, har du brugt programmeringssprog. De er fantastiske måder at få en computer til at gøre, hvad du vil have det til. Måske har du endda dyve dybt og programmeret i samling eller maskinkode. Mange vil aldrig vende tilbage. Men nogle spekulerer på, hvordan kan jeg torturere mig mere ved at lave mere lavt niveau programmering? Jeg vil gerne vide mere om, hvordan programmeringssprog er lavet!, Alt sjov til side, at skrive et nyt sprog er ikke så slemt, som det lyder, så hvis du endda har en mild nysgerrighed, vil jeg foreslå, at du holder dig rundt og ser, hvad det handler om.
dette indlæg er beregnet til at give et simpelt dykke ind i, hvordan et programmeringssprog kan laves, og hvordan du kan lave dit eget specielle sprog. Måske endda navngive det efter dig selv. Hvem ved.
Jeg vedder også på, at dette virker som en utrolig skræmmende opgave at påtage sig. Bare rolig, for jeg har overvejet dette. Jeg gjorde mit bedste for at forklare alt relativt enkelt uden at gå på for mange tangenter., Ved udgangen af dette indlæg vil du være i stand til at oprette dit eget programmeringssprog (der vil være et par dele), men der er mere. At vide, hvad der foregår under hætten, vil gøre dig bedre til fejlfinding. Du forstår bedre nye programmeringssprog, og hvorfor de træffer de beslutninger, de gør. Du kan have et programmeringssprog opkaldt efter dig selv, hvis jeg ikke nævnte det før. Det er også rigtig sjovt. I hvert fald til mig.
oversættere og tolke
programmeringssprog er generelt på højt niveau. Det vil sige, du kigger ikke på 0 ‘er og 1’ er eller registre og samlingskode., Men din computer forstår kun 0 ‘er og 1’ er, så den har brug for en måde at flytte fra det, du læser let, til hvad maskinen nemt kan læse. Denne oversættelse kan ske gennem kompilering eller fortolkning.kompilering er processen med at omdanne en hel kildefil af kildesproget til et målsprog. Til vores formål vil vi overveje at kompilere ned fra dit helt nye, topmoderne sprog, helt ned til kørbar maskinkode.,

mit mål er at få “magien” til at forsvinde
fortolkning er processen med at udføre kode i en kildefil mere eller mindre direkte. Jeg vil lade dig tro, det er magi for dette.
så hvordan går du fra let at læse kildesprog til svært at forstå målsprog?
faser af en Compiler
en compiler kan opdeles i faser på forskellige måder, men der er en måde, der er mest almindelig., Det giver kun en lille smule mening første gang du ser det, men her går det:
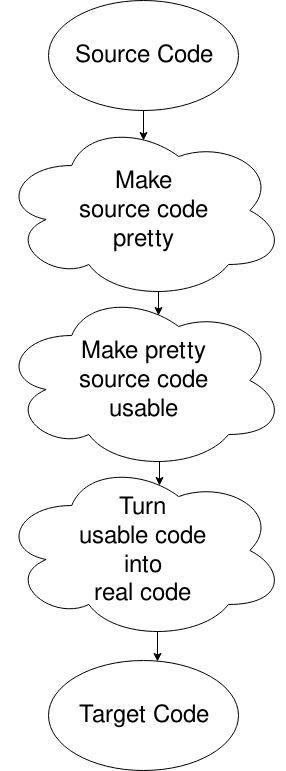
Ups, jeg valgte det forkerte diagram, men det vil gøre. Dybest set får du kildefilen, du sætter den i et format, som computeren ønsker (fjerner hvidt rum og sådan noget), ændrer det til noget, computeren kan bevæge sig godt ind og derefter generere koden derfra. Der er mere i det. Det er til en anden gang, eller til din egen forskning, hvis din nysgerrighed dræber dig.,
Leksikalsk Analyse
AKA “at Gøre kildekoden temmelig”
Overvej følgende, helt gjort op sprog, som er dybest set bare en lommeregner med semikolon:
// source.ect 3 + 3.2; 5.0 / 1.9; 6 * 2;computer ikke brug for alt dette. Rum er bare for vores smålige sind. Og nye linjer? Ingen har brug for dem. Computeren forvandler denne kode, som du ser, til en strøm af tokens, som den kan bruge i stedet for kildefilen., Grundlæggende ved det, at 3 er et heltal, 3.2 er en flyder, og + er noget, der fungerer på disse to værdier. Det er alt, hvad computeren virkelig har brug for at komme forbi. Det er den leksikalske analysator job at give disse tokens i stedet for et kildeprogram.
hvordan det gør det er virkelig ret simpelt: giv le .er (en mindre prætentiøs klingende måde at sige leksikalsk analysator) nogle ting at forvente, så fortæl det hvad man skal gøre, når det ser de ting. Disse kaldes regler., Her er et eksempel:
int cout << "I see an integer!" << endl;Når en int, der kommer gennem lexer og denne regel er gennemført, vil du blive mødt med en helt indlysende, “jeg kan se et heltal!” udråbstegn. Det er ikke sådan, vi bruger le .eren, men det er nyttigt at se, at kodeudførelsen er vilkårlig: der er ikke regler, som du skal gøre noget objekt og returnere det, det er bare almindelig gammel kode. Kan endda bruge mere end en linje ved at omringe den med seler.,
forresten bruger vi noget, der hedder FLE.til at gøre vores le .ing. Det gør tingene temmelig let, men intet stopper dig fra bare at lave et program, der gør det selv.
for At få en forståelse af, hvordan vi vil bruge flex, kig på dette eksempel:
Dette introducerer et par nye begreber, så lad os gå over dem:
%% bruges til at adskille dele af den .le. – filen. Det første afsnit er erklæringer-grundlæggende variabler for at gøre le .eren mere læsbar., Det er også hvor du importerer, omgivet af %{ og %}.
anden del er reglerne, som vi så før. Disse er dybest set en stor if else if blok. Det vil udføre linjen med den længste kamp. Således, selv hvis du ændrer rækkefølgen af float og int, den flyder stadig kamp, som matcher 3 tegn i 3.2 er mere end 1 karakter af 3., Bemærk, at hvis ingen af disse regler er matchet, det går til standard regel, blot udskrive tegnet til standard ud. Du kan derefter bruge yytext for at henvise til, hvad den så, der matchede denne regel.
tredje del er koden, som simpelthen er C eller C++ kildekode, der køres ved udførelse. yylex(); er et funktionskald, der kører le .eren. Du kan også få det til at læse input fra en fil, men som standard læses det fra standardindgang.
sig, at du oprettede disse to filer som source.ect og scanner.lex., Vi kan skabe et C++ – program ved brug af flex kommando (givet du har flex installeret), så kompilere ned og input vores kilde-kode for at nå vores fantastiske udskrive erklæringer. Lad os sætte dette i aktion!
Hej, cool! Du skriver bare C++ – kode, der matcher input til Regler for at gøre noget.
nu, hvordan bruger compilere dette? Generelt, i stedet for at udskrive noget, vil hver regel returnere noget – et token! Disse tokens kan defineres i den næste del af compileren…,
Syntaksanalysator
AKA “gør smuk kildekode brugbar”
det er tid til at have det sjovt! Når vi kommer her, begynder vi at definere programmets struktur. Parseren er lige givet en strøm af tokens, og den skal matche elementer i denne strøm for at få kildekoden til at have struktur, der er brugbar. For at gøre dette bruger den grammatikker, den ting du sandsynligvis så i en teoriklasse eller hørte din underlige ven geeking ud om. De er utroligt magtfulde, og der er så meget at gå ind på, men jeg vil bare give det, du har brug for at vide for vores sorta dum parser.,grundlæggende matcher grammatik ikke-terminale symboler til en kombination af terminal-og ikke-terminalsymboler. Terminaler er blade af træet; ikke-terminaler har børn. Du skal ikke bekymre dig om det, hvis det ikke giver mening, koden vil sandsynligvis være mere forståelig.
Vi bruger en parsergenerator kaldet Bison. Denne gang deler jeg filen op i sektioner til forklaringsformål. For det første skal erklæringerne:
den første del se bekendt ud: vi importerer ting, som vi vil bruge. Derefter bliver det lidt mere vanskeligt.,Unionen er en kortlægning af en “rigtig” C++ – type til det, vi vil kalde det i hele dette program. Så, når vi ser intVal, du kan erstatte, at der i dit hoved med int, og når vi ser floatVal, du kan erstatte, at der i dit hoved med float. Du vil se hvorfor senere.
næste kommer vi til symbolerne. Du kan opdele disse i dit hoved som terminaler og ikke-terminaler, som med de grammatikker, vi talte om før. Store bogstaver betyder terminaler, så de ikke fortsætter med at udvide., Små bogstaver betyder ikke-terminaler, så de fortsætter med at udvide. Det er bare konvention.
hver erklæring (begyndende med %) erklærer et symbol. Først ser vi, at vi starter med en ikke-terminal program. Derefter definerer vi nogle tokens. <> parentes definere return type: så INTEGER_LITERAL terminal returnerer en intVal. SEMI terminal returnerer intet., En lignende ting der kan gøres med non-terminaler ved hjælp af type, som det kan ses, når man definerer exp som en non-terminal, der returnerer en floatVal.
endelig får vi forrang. Vi kender PEMDAS, eller hvad som helst andet akronym du måske har lært, som fortæller dig nogle enkle forrang regler: multiplikation kommer før tilføjelse, etc. Nu erklærer vi det her på en underlig måde. For det første betyder lavere på listen højere forrang. For det andet kan du undre dig over, hvad left betyder., Det er associativitet: temmelig meget, hvis vi har a op b op c gør a og b gå sammen, eller måske b og c? De fleste af vores operatører gør det tidligere, hvor a og b går sammen først: det kaldes venstre associativitet. Nogle operatører, som potensopløftning, gøre det modsatte: a^b^c forventer, at du hæver b^c, så a^(b^c). Det vil vi dog ikke beskæftige os med., Se på Bisonsiden, hvis du vil have flere detaljer.
Okay jeg keder dig nok nok med erklæringer, her er grammatikreglerne:
Dette er den grammatik, vi talte om før. Hvis du ikke er bekendt med grammatik, er det ret simpelt: venstre side kan blive til noget af tingene på højre side, adskilt med | (logisk or). Hvis det kan gå ned ad flere stier, er det et nej, vi kalder det en tvetydig grammatik., Dette er ikke tvetydigt på grund af vores forrangserklæringer – hvis vi ændrer det, så plus ikke længere efterlades associativt, men i stedet erklæres som en token som SEMI, ser vi, at vi får en skift/reducer konflikt. Vil du vide mere? Se op, hvordan Bison fungerer, tip, den bruger en LR-parsingalgoritme.
Okay, så exp kan blive et af disse tilfælde: en INTEGER_LITERAL, a FLOAT_LITERAL osv. Bemærk, at det også er rekursivt, så exp kan blive til to exp., Dette giver os mulighed for at bruge komplekse udtryk, som 1 + 2 / 3 * 5. Hver exp, husk, returnerer en float type.
hvad der er inde i parenteserne er det samme som vi så med Le .er: vilkårlig C++ – kode, men med mere underligt syntaktisk sukker. I dette tilfælde har vi særlige variabler forankret med $. Variablen $$ er dybest set det, der returneres. $1 er det, der returneres af det første argument, $2 hvad returneres af det andet osv., Ved “argument” jeg mener dele af den grammatiske regel: så reglen exp PLUS exp er argument 1 exp argument 2 PLUS, og argumentet 3 exp. Så i vores kodeudførelse tilføjer vi det første udtryks resultat til det tredje.
endelig, når det kommer tilbage til program ikke-terminal, vil det udskrive resultatet af erklæringen. Et program er i dette tilfælde en masse udsagn, hvor udsagn er et udtryk efterfulgt af et semikolon.
lad os nu skrive kodedelen., Dette er, hvad der faktisk vil blive kørt, når vi går gennem parseren:
Okay, dette begynder at blive interessant. Vores vigtigste funktion læser nu fra en fil, som det første argument i stedet for fra standard i, og vi har tilføjet nogle fejlkode. Det er temmelig selvforklarende, og kommentarer gør et godt stykke arbejde med at forklare, hvad der foregår, så jeg overlader det som en øvelse for læseren at finde ud af det. Alt du behøver at vide er nu vi er tilbage til Le !er at give tokens til parseren! Her er vores nye le !er:
Hej, det er faktisk mindre nu!, Hvad vi ser er, at i stedet for at udskrive, returnerer vi terminalsymboler. Nogle af disse, som ints og floats, sætter vi først værdien, før vi går videre (yylval er returværdien af terminalsymbolet). Bortset fra det giver det bare parseren en strøm af terminal tokens til brug efter eget skøn.Cool, lad os køre det så!
der går vi – vores parser udskriver de korrekte værdier! Men dette er ikke rigtig en compiler, det kører bare C++ – kode, der udfører det, vi ønsker. For at lave en compiler ønsker vi at omdanne dette til maskinkode., For at gøre det skal vi tilføje lidt mere…
indtil næste gang…
Jeg indser nu, at dette indlæg vil være meget længere, end jeg forestillede mig, så jeg regnede med, at jeg ville afslutte denne her. Vi har dybest set en fungerende le .er og parser, så det er et godt stoppunkt.
Jeg har lagt kildekoden på min Github, hvis du er nysgerrig efter at se det endelige produkt. Efterhånden som flere indlæg frigives, vil repo se mere aktivitet.,
i betragtning af vores le .er og parser kan vi nu generere en mellemliggende repræsentation af vores kode, der endelig kan konverteres til ægte maskinkode, og jeg viser dig nøjagtigt, hvordan du gør det.
yderligere ressourcer
Hvis du tilfældigvis ønsker mere information om noget, der er dækket her, har jeg linket nogle ting for at komme i gang. Jeg gik lige over meget, så dette er min chance for at vise dig, hvordan du dykker ned i disse emner.Åh, forresten, hvis du ikke kunne lide mine faser af en compiler, er her et faktisk diagram. Jeg slap stadig af symbolbordet og fejlhåndteringen., Bemærk også, at mange diagrammer er forskellige fra dette, men det viser bedst, hvad vi er bekymrede for.

Skriv et svar