Se også Pearson korrelationer – hurtig introduktion.
- Korrelationstest – Hvad er det?
- Null hypotese
- antagelser
- Korrelationstest i SPSS
- rapportering
Korrelationstest – Hvad er det?
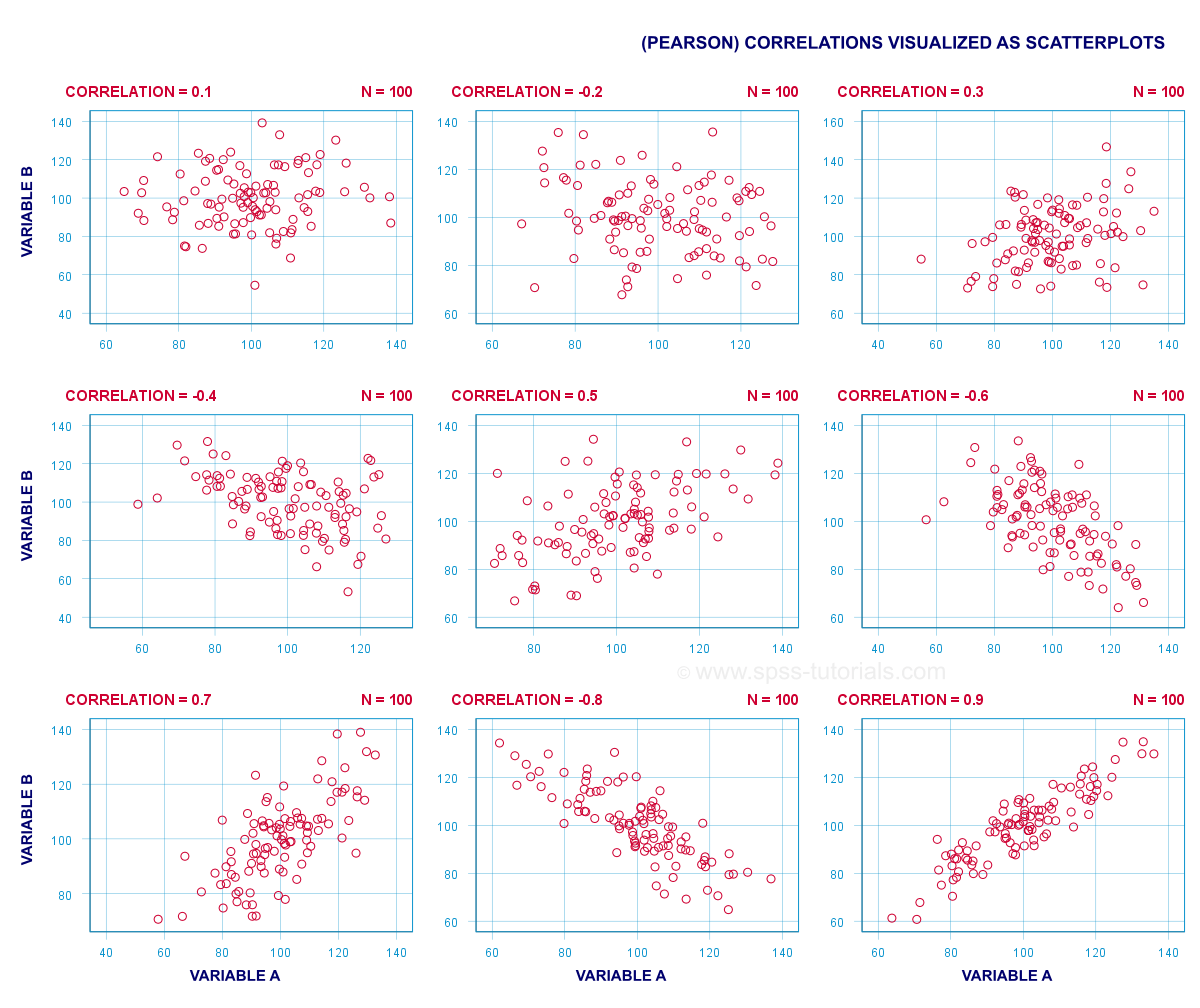
A (Pearson) korrelation er et tal mellem -1 og +1, der angiver, i hvilket omfang 2 kvantitative variabler er lineært relaterede. Det forstås bedst ved at se på nogle scatterplots.,
I kort,
- en korrelation på -1 indikerer en perfekt lineær faldende forhold: højere score på en variabel, der indebærer lavere score på de øvrige variable.
- en korrelation på 0 betyder, at der ikke er nogen lineær relation mellem 2 variabler overhovedet. Der kan dog være en (stærk) ikke-lineær relation alligevel.
- en korrelation på 1 indikerer en perfekt stigende lineær relation: højere score på en variabel er forbundet med højere score på den anden variabel.,
Nulhypotese
en korrelationstest (normalt) tester nulhypotesen om, at befolkningskorrelationen er nul.Data indeholder ofte blot et udsnit fra en (meget) større befolkning: jeg undersøgte 100 kunder (prøve), men jeg er virkelig interesseret i alle mine 100.000 kunder (befolkning). Prøveresultater adskiller sig typisk noget fra befolkningsresultater. Så at finde en ikke-nul-korrelation i min prøve viser det ikke 2 variabler er korrelerede i hele min befolkning; hvis befolkningskorrelationen virkelig er nul, Jeg kan let finde en lille korrelation i min prøve., Imidlertid er det meget usandsynligt at finde en stærk korrelation i dette tilfælde og antyder, at min befolkningskorrelation trods alt ikke var nul.
Korrelationstest – antagelser
beregning og fortolkning af korrelationskoefficienter kræver ingen antagelser. Imidlertid antager den statistiske signifikanstest for korrelationer
- uafhængige observationer;
- normalitet: vores 2 variabler skal følge en bivariat normalfordeling i vores befolkning. Denne antagelse er ikke nødvendig for stikprøvestørrelser på N = 25 eller mere.,For rimelige stikprøvestørrelser sikrer central limit theorem, at prøveudtagningsfordelingen vil være normal.
SPSS – hurtig datakontrol
lad os køre nogle korrelationstest i SPSS nu. Vi bruger unge.sav, en datafil, der indeholder psykologiske testdata om 128 børn mellem 12 og 14 år. En del af dens variable visning er vist nedenfor.
lad os først sørge for, at vores data er plausible i første omgang, før vi kører nogen korrelationer., Da alle 5 variabler er metriske, vil vi hurtigt inspicere deres histogrammer ved at køre syntaksen nedenfor.*hurtig data check: histogrammer over alle relevante variabler.
frekvenser i to til wellellb
/format notable
/histogram.
Histogramudgang
vores histogrammer fortæller os meget: vores variabler har mellem 5 og 10 manglende værdier. Deres midler er tæt på 100 med standardafvigelser omkring 15 – hvilket er godt, fordi det er sådan, disse test er blevet kalibreret. En ting generer mig, selvom, og det er vist nedenfor.,
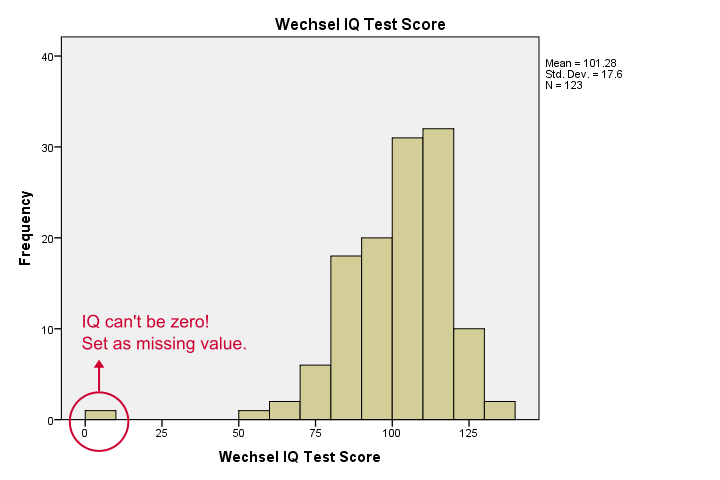
det ser ud til, at nogen scorede nul på nogle tests-hvilket slet ikke er sandsynligt. Hvis vi ignorerer dette, vil vores korrelationer være alvorligt partiske. Lad os sortere vores sager, se hvad der foregår og indstille nogle manglende værdier, før vi fortsætter.
*En sag har nul på begge tests. Indstil som manglende værdi, før du fortsætter.
manglende værdier i ANX an anxi (0).
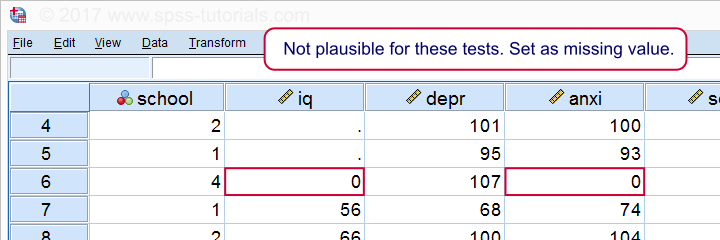
Hvis vi nu kører vores histogrammer igen, ser vi, at alle distributioner ser plausible ud., Først nu skal vi fortsætte med at køre de faktiske korrelationer.
kørsel af en Korrelationstest i SPSS
lad os først navigere for at analysere![]() korrelere
korrelere![]() Bivariere som vist nedenfor.
Bivariere som vist nedenfor.
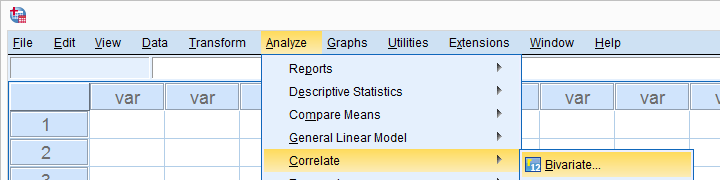
Flyt alle relevante variabler i feltet variabler. Du vil sandsynligvis ikke ændre noget andet her.
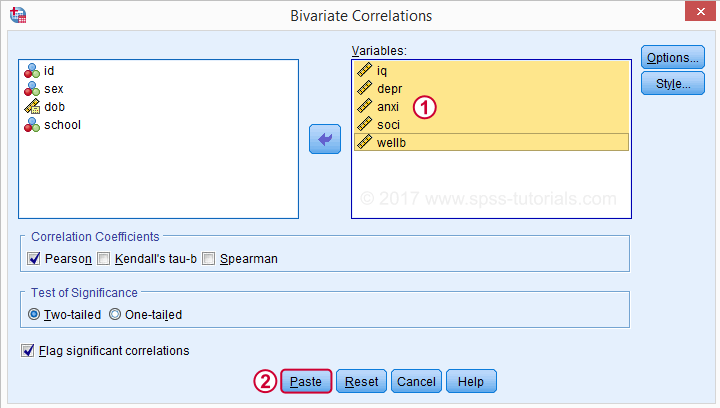
Klik på Indsæt resulterer i syntaksen nedenfor. Lad os køre det.
SPSS korrelationer syntaks
KORRELATIONER
/VARIABLER=iq depr anxi professionelle wellb
/PRINT=TWOTAIL NOSIG
/MISSING=PARVISE.* kortere version, skaber nøjagtig samme output.
korrelationer i.til wellellb
/print nosig.
Korrelationsudgang
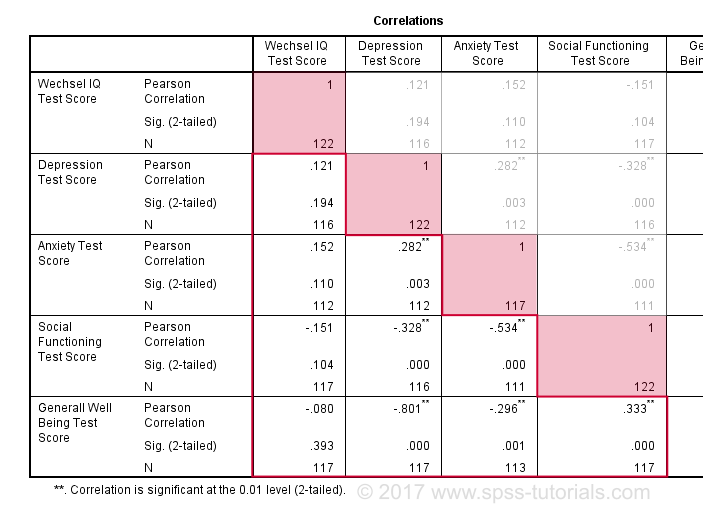
som standard opretter SPSS altid en fuld korrelationsmatri.. Hver korrelation vises to gange: over og under hoveddiagonalen. Korrelationerne på hoveddiagonalen er korrelationerne mellem hver variabel og sig selv-derfor er de alle 1 og slet ikke interessante. De 10 korrelationer under diagonalen er, hvad vi har brug for., Som en tommelfingerregel, en korrelation er statistisk signifikant, hvis dens “Sig. (2-tailed)” < 0.05.Lad os nu se nærmere på vores resultater: den stærkeste sammenhæng er mellem depression og overordnet velvære : r = -0.801. Den er baseret på N = 117 børn og dens 2-tailed betydning, p = 0,000. Dette betyder, at der er en 0.000 Sandsynlighed for at finde denne prøvekorrelation-eller en større – hvis den faktiske befolkningskorrelation er nul.
Bemærk, at I.ikke korrelerer med noget. Dens stærkeste korrelation er 0.152 med angst, men p = 0.,11 så det er ikke statistisk signifikant forskelligt fra nul. Det vil sige, at der er en 0,11 chance for at finde det, hvis befolkningskorrelationen er nul. Denne sammenhæng er for lille til at afvise nulhypotesen.
som sådan angiver vores 10 korrelationer, i hvilket omfang hvert par variabler er lineært relaterede. Endelig bemærke, at hver korrelation beregnes på en lidt anden N-spænder fra 111 til 117. Dette skyldes, at SPSS bruger parvis sletning af manglende værdier som standard for korrelationer.,
Scatterplots
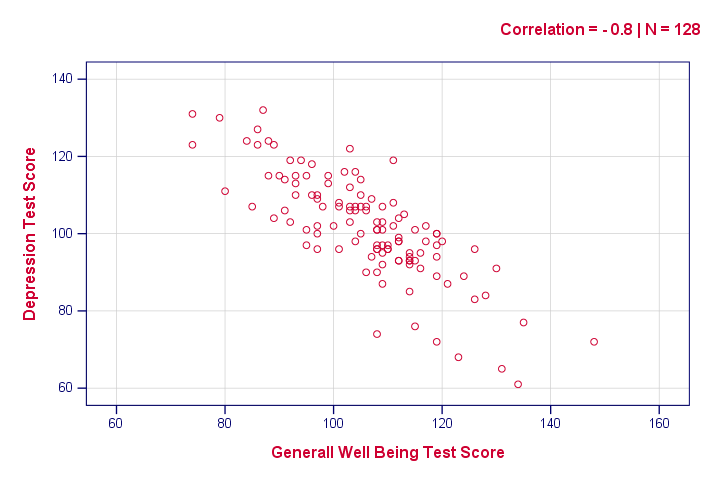
strengt bør vi også inspicere alle scatterplots blandt vores variabler. Når alt kommer til alt, kan variabler, der ikke korrelerer, stadig være relateret på en ikke-lineær måde. Men for mere end 5 eller 6 variabler, antallet af mulige scatterplots eksploderer så vi ofte springe inspicere dem. Se dog SPSS-Opret alle Scatterplots-værktøjer.syntaksen nedenfor skaber kun en scatterplot, bare for at få en ide om, hvordan vores forhold ser ud. Resultatet viser dog ikke noget uventet.
graf
/scatter wellellb med depr
/undertekst “Correlation = – 0.8 | n = 128”.
rapportering af en Korrelationstest
figuren nedenfor viser det mest basale format, som APA anbefaler til rapportering af korrelationer. Det er vigtigt, at tabellen angiver, hvilke korrelationer der er statistisk signifikante ved p < 0.05 og måske p < 0.01. Se også SPSS korrelationer i APA-Format.
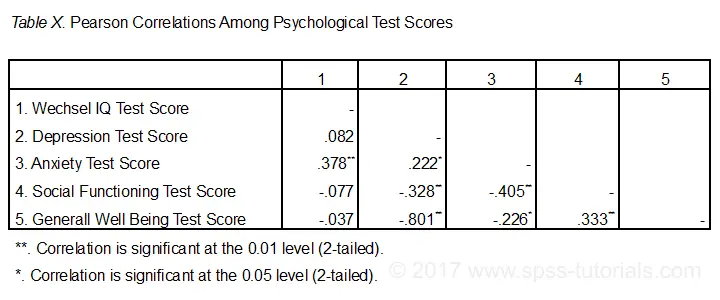
Hvis det er muligt, skal du også rapportere konfidensintervallerne for dine korrelationer., Mærkeligt nok inkluderer SPSS ikke dem. Se dog SPSS-konfidensintervaller for Korrelationsværktøj.
tak for læsning!
Skriv et svar