Si eres un desarrollador, has usado lenguajes de programación. Son formas increíbles de hacer que una computadora haga lo que tú quieres. Tal vez incluso has buceado profundamente y programado en ensamblado o código de máquina. Muchos nunca quieren volver. Pero algunos se preguntan, ¿Cómo puedo torturarme más haciendo más programación de bajo nivel? ¡Quiero saber más sobre cómo se hacen los lenguajes de programación!, Dejando de lado las bromas, escribir un nuevo idioma no es tan malo como suena, así que si tienes una curiosidad leve, te sugiero que te quedes y veas de qué se trata.
este post está destinado a dar una simple inmersión en cómo se puede hacer un lenguaje de programación, y cómo puedes hacer tu propio lenguaje especial. Tal vez incluso ponerle tu nombre. Quién sabe.
también apuesto a que esto parece una tarea increíblemente desalentadora para asumir. No te preocupes, porque he considerado esto. Hice todo lo posible para explicar todo de forma relativamente simple sin ir en demasiadas tangentes., Al final de este post, podrás crear tu propio lenguaje de programación (habrá algunas partes), pero hay más. Saber lo que sucede debajo del capó te hará mejor en la depuración. Comprenderás mejor los nuevos lenguajes de programación y por qué toman las decisiones que toman. Puedes tener un lenguaje de programación con tu nombre, si no lo mencioné antes. Además, es muy divertido. Al menos para mí.
los compiladores e intérpretes
los lenguajes de programación son generalmente de alto nivel. Es decir, no estás mirando 0s y 1s, ni registros y código ensamblador., Pero, su computadora solo entiende 0s y 1s, por lo que necesita una forma de pasar de lo que lee fácilmente a lo que la máquina puede leer fácilmente. Esa traducción puede hacerse mediante compilación o interpretación.
la compilación es el proceso de convertir un archivo fuente completo del idioma fuente en un idioma de destino. Para nuestros propósitos, pensaremos en compilar desde su nuevo lenguaje de vanguardia, hasta el código máquina ejecutable.,

Mi objetivo es hacer que la» magia » desaparezca
La interpretación es el proceso de ejecutar código en un archivo fuente más o menos directamente. Te dejaré pensar que es magia para esto.
entonces, ¿cómo pasar de un idioma fuente fácil de leer a un idioma objetivo difícil de entender?
fases de un compilador
un compilador se puede dividir en fases de varias maneras, pero hay una forma que es más común., Tiene solo una pequeña cantidad de sentido la primera vez que lo ves, pero aquí va:
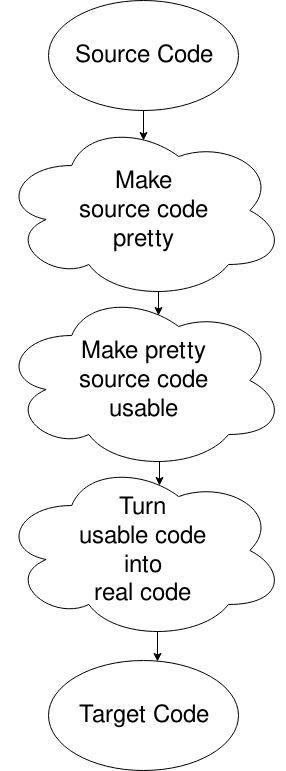
Oops, elegí el diagrama equivocado, pero esto servirá. Básicamente, obtienes el archivo fuente, lo pones en un formato que la computadora quiere (eliminando el espacio en blanco y cosas por el estilo), lo cambias en algo que la computadora puede mover bien, y luego generas el código a partir de eso. Hay más que eso. Eso es para otro momento, o para tu propia investigación si tu curiosidad te está matando.,
Lexical Analysis
AKA «Making source code pretty»
considere el siguiente lenguaje completamente inventado que es básicamente solo una calculadora con punto y coma:
// source.ect 3 + 3.2; 5.0 / 1.9; 6 * 2;e eso. Los espacios son sólo para nuestras mentes mezquinas. ¿Y nuevas líneas? Nadie los necesita. El ordenador convierte este código que ves en un flujo de tokens que puede utilizar en lugar del archivo de origen., Básicamente, se sabe que el3es un número entero,3.2es un float, y+es algo que opera en esos dos valores. Eso es todo lo que la computadora necesita para sobrevivir. Es el trabajo del analizador léxico proporcionar estos tokens en lugar de un programa fuente.
Cómo lo hace Es realmente bastante simple: dale al lexer (una forma menos pretenciosa de decir lexical analyzer) algunas cosas que esperar, luego dile qué hacer cuando vea esas cosas. Estas se llaman reglas., Aquí hay un ejemplo:
int cout << "I see an integer!" << endl;Cuando un int viene a través del lexer y esta regla se ejecuta, se le dará la bienvenida con un bastante obvio » veo un entero!» exclamación. Así no es como vamos a usar el lexer, pero es útil ver que la ejecución de código es arbitraria: no hay reglas que tienes que hacer algún objeto y devolverlo, es solo código antiguo normal. Incluso puede usar más de una línea rodeándola con frenos.,
Por cierto, usaremos algo llamado FLEX para hacer nuestro lexing. Hace las cosas bastante fáciles, pero nada te impide hacer un programa que lo haga tú mismo.
para obtener una comprensión de cómo vamos a utilizar flex, mira este ejemplo:
esto introduce algunos conceptos nuevos, así que vamos a repasar:
%% se utiliza para separar secciones de la .archivo lex. La primera sección es declaraciones – básicamente variables para hacer el lexer más legible., También es donde importa, rodeado por %{ y %}.
La segunda parte son las reglas, que vimos antes. Estos son, básicamente, una gran if else if bloquear. Ejecutará la línea con la coincidencia más larga. Por lo tanto, incluso si cambia el orden del flotador e int, los flotadores seguirán coincidiendo, ya que coincidir con 3 caracteres de 3.2 es más de 1 carácter de 3., Tenga en cuenta que si ninguna de estas reglas coincide, va a la regla predeterminada, simplemente imprimiendo el carácter a standard out. Luego puede usar yytext para referirse a lo que vio que coincidía con esa regla.
tercera parte es el código, que es simplemente C o c++ código fuente que se ejecuta en la ejecución. yylex(); es una llamada a función que ejecuta el lexer. También puede hacer que lea la entrada de un archivo, pero por defecto lee la entrada estándar.
Dicen que han creado estos dos archivos como source.ect y scanner.lex., Podemos crear un programa C++ usando el comando flex(dado que tiene flex instalado), luego compilarlo e ingresar nuestro código fuente para llegar a nuestras instrucciones de impresión impresionantes. ¡Pongamos esto en acción!
Hey, cool! Solo estás escribiendo código C++ que coincide con la entrada de reglas para hacer algo.
Ahora, ¿cómo usan esto los compiladores? En general, en lugar de imprimir algo, cada regla devolverá algo – un token! Estos tokens se pueden definir en la siguiente parte del compilador…,
Syntax Analyzer
AKA «Making pretty source code usable»
¡Es hora de divertirse! Una vez que llegamos aquí, empezamos a definir la estructura del programa. Al analizador se le da un flujo de tokens, y tiene que coincidir con los elementos de este flujo para que el código fuente tenga una estructura que sea utilizable. Para hacer esto, usa gramáticas, esa cosa que probablemente viste en una clase de teoría o escuchaste a tu extraño amigo. Son increíblemente poderosos, y hay mucho en lo que entrar, pero te daré lo que necesitas saber para nuestro parser tonto.,
básicamente, las gramáticas hacen coincidir símbolos No terminales con alguna combinación de símbolos terminales y no terminales. Los terminales son hojas del árbol; los no terminales tienen hijos. No te preocupes si eso no tiene sentido, el código probablemente será más comprensible.
usaremos un generador de analizador llamado Bison. Esta vez, dividiré el archivo en secciones para fines de explicación. Primero, las declaraciones:
la primera parte debería parecer familiar: estamos importando cosas que queremos usar. Después de eso se pone un poco más complicado.,
La Unión es un mapeo de un tipo c++» real » a lo que vamos a llamar a lo largo de este programa. Así, cuando vemos intVal, se puede sustituir en su cabeza con la etiqueta int, y cuando vemos floatVal, se puede sustituir en su cabeza con la etiqueta float. Ya verás por qué más tarde.
a continuación llegamos a los símbolos. Puedes dividirlos en tu cabeza como terminales y no terminales, como con las gramáticas de las que hablamos antes. Las letras mayúsculas significan terminales, por lo que no continúan expandiéndose., Minúsculas significa que no son terminales, por lo que continúan expandiéndose. Es una convención.
cada declaración (comenzando con %) declara algún símbolo. Primero, vemos que comenzamos con un no terminal program. Luego, definimos algunos tokens. Los corchetes<> definen el tipo de retorno: por lo tanto, el terminal INTEGER_LITERAL devuelve un intVal. El terminal SEMI no devuelve nada., Una cosa similar se puede hacer con no-terminales usando type, como se puede ver al definir expcomo un no-terminal que devuelve un floatVal.
finalmente entramos en precedencia. Sabemos PEMDAS, o cualquier otro acrónimo que hayas aprendido, que te dice algunas reglas de precedencia simples:la multiplicación viene antes de la suma, etc. Ahora, declaramos que aquí de una manera extraña. En primer lugar, más bajo en la lista significa mayor precedencia. En segundo lugar, puede preguntarse qué significa left., Que la asociatividad: bastante, si tenemos a op b op c, do a y b ir juntos, o tal vez b y c? La mayoría de nuestros operadores hacen lo primero, donde ay b van juntos primero: eso se llama asociatividad izquierda. Algunos operadores, como exponenciación, hacer lo contrario: a^b^c espera que recaude b^c entonces a^(b^c). Sin embargo, no nos ocuparemos de eso., Mira la página de bisontes si quieres más detalles.
bien, probablemente te aburrí lo suficiente con las declaraciones, aquí están las reglas gramaticales:
Esta es la gramática de la que estábamos hablando antes. Si no estás familiarizado con las gramáticas, es bastante simple: el lado izquierdo puede convertirse en cualquiera de las cosas del lado derecho, separadas con | (lógico or). Si puede ir por múltiples caminos, eso es un no-no, lo llamamos una gramática ambigua., Esto no es ambiguo debido a nuestras declaraciones de precedencia: si lo cambiamos para que plus ya no sea asociativo, sino que se declare como token como SEMI, vemos que obtenemos un conflicto shift/reduce. Quieres saber más? Mira cómo funciona Bison, pista, utiliza un algoritmo de análisis LR.
Está bien, por lo que exppuede convertirse en uno de esos casos: an INTEGER_LITERAL, a FLOAT_LITERAL, etc. Nota también es recursivo, por lo que exp se puede convertir en dos exp., Esto nos permite usar expresiones complejas, como 1 + 2 / 3 * 5. Cada exp, recuerde, devuelve un tipo flotante.
lo que está dentro de los corchetes es lo mismo que vimos con el lexer: código C++ arbitrario, pero con azúcar sintáctico más raro. En este caso, tenemos variables especiales antepuestas con $. La variable $$ es básicamente lo que se devuelve. $1 es lo que devuelve el primer argumento, $2 lo que devuelve el segundo, etc., Por «argumento»me refiero a partes de la regla gramatical: así que la regla exp PLUS exp tiene el argumento 1 exp, el argumento 2 PLUS, y el argumento 3 exp. Así, en nuestra ejecución de código, añadimos el resultado de la primera expresión a la tercera.
finalmente, una vez que vuelva a la program no terminal, imprimirá el resultado de la instrucción. Un programa, en este caso, es un montón de sentencias, donde las sentencias son una expresión seguida de un punto y coma.
Ahora vamos a escribir la parte del código., Esto es lo que realmente se ejecutará cuando pasemos por el analizador:
bien, esto está empezando a ponerse interesante. Nuestra función principal Ahora lee de un archivo proporcionado por el primer argumento en lugar de Estándar en, y hemos añadido un código de error. Es bastante autoexplicativo, y los comentarios hacen un buen trabajo para explicar lo que está pasando, así que lo dejaré como un ejercicio para que el lector lo resuelva. Todo lo que necesitas saber es que ahora estamos de vuelta al lexer para proporcionar los tokens para el analizador! Aquí está nuestro nuevo lexer:
Hey, eso es realmente más pequeño ahora!, Lo que vemos es que en lugar de imprimir, estamos devolviendo símbolos terminales. Algunos de estos, como ints y floats, primero establecemos el valor antes de Continuar (yylval es el valor devuelto del símbolo de terminal). Aparte de eso, solo está dando al analizador un flujo de tokens de terminal para usar a su discreción.
genial, vamos a ejecutarlo entonces!
ahí vamos – nuestro analizador imprime los valores correctos! Pero esto no es realmente un compilador, solo ejecuta código C++ que ejecuta lo que queremos. Para hacer un compilador, queremos convertir esto en código máquina., Para ello, necesitamos añadir un poco más…
hasta la próxima vez…
ahora me estoy dando cuenta de que este post será mucho más largo de lo que imaginaba, así que pensé que terminaría este aquí. Básicamente tenemos un lexer y un analizador que funcionan, así que es un buen punto de parada.
he puesto el código fuente en mi Github, si tienes curiosidad por ver el producto final. A medida que se publiquen más publicaciones, ese repositorio verá más actividad.,
dado nuestro lexer y parser, ahora podemos generar una representación intermedia de nuestro código que finalmente se puede convertir en código máquina real, y te mostraré exactamente cómo hacerlo.
recursos adicionales
Si quieres más información sobre cualquier cosa cubierta aquí, he vinculado algunas cosas para comenzar. Fui mucho, así que esta es mi oportunidad de mostrarles cómo sumergirse en esos temas.
Oh, por cierto, si no te gustaron mis fases de un compilador, aquí hay un diagrama real. Todavía dejé la tabla de símbolos y el controlador de errores., También tenga en cuenta que muchos diagramas son diferentes de esto, pero esto demuestra mejor lo que nos preocupa.

Deja una respuesta