Jos olet kehittäjä, olet käyttänyt ohjelmointikieliä. Ne ovat mahtavia tapoja saada tietokone tekemään mitä haluat. Ehkä olet jopa sukeltanut syvälle ja ohjelmoinut kokoonpanoon tai koneen koodiin. Moni ei koskaan halua palata. Mutta jotkut ihmettelevät, miten voin kiduttaa itseäni enemmän tekemällä matalampaa ohjelmointia? Haluan tietää enemmän siitä, miten ohjelmointikielet tehdään!, Uuden kielen kirjoittaminen ei ole niin pahaa kuin miltä se kuulostaa, joten jos sinulla on edes lievää uteliaisuutta, ehdotan, että jäät katsomaan, mistä on kyse.
Tämä viesti on tarkoitettu antamaan yksinkertaisia sukeltaa, miten ohjelmointikieli voidaan tehdä, ja miten voit tehdä oma erityinen kieli. Ehkä jopa nimeät sen itsesi mukaan. Kuka tietää.
veikkaan myös, että tämä tuntuu uskomattoman pelottavalta tehtävältä ottaa. Älä huoli, sillä olen harkinnut tätä. Tein parhaani selittääkseni kaiken suhteellisen yksinkertaisesti menemättä liian moneen tangenttiin., Tämän jälkeen, voit luoda oman ohjelmointikielen (siellä on muutamia osia), mutta siellä on enemmän. Kun tietää, mitä konepellin alla tapahtuu, tekee sinusta paremman vianetsinnän. Sinun on parempi ymmärtää uusia ohjelmointikieliä ja miksi he tekevät päätöksiä, joita he tekevät. Voit nimetä ohjelmointikielen itsesi mukaan, jos en maininnut siitä aiemmin. Se on myös todella hauskaa. Ainakin minulle.
Kääntäjät ja Tulkit
ohjelmointikielet ovat yleensä korkean tason. Toisin sanoen, et katso 0s ja 1s, eikä rekisterit ja kokoonpano koodi., Mutta, tietokone ymmärtää vain 0s ja 1s, joten se tarvitsee tapa siirtyä mitä luet helposti, mitä kone voi lukea helposti. Käännös voidaan tehdä kokoamalla tai tulkitsemalla.
Kooste on prosessi kääntämällä koko lähdetiedoston lähteestä kielestä kohdekielelle. Meidän kannalta, me ajatella kääntäminen alas upouusi, state of the art kieli, kaikki alas ajettavissa koneen koodi.,

– tavoitteenani on tehdä ”taika” katoaa
Tulkinta on prosessi, jossa täytäntöönpanovaltion koodia source-tiedoston, enemmän tai vähemmän suoraan. Annan sinun luulla, että se on taikaa tähän.
Joten, miten voit mennä helppo lukea lähde kieltä on vaikea ymmärtää kohdekielen?
Vaiheet Compiler
kääntäjä voidaan jakaa vaiheisiin eri tavoin, mutta on yksi tapa, joka on yleisin., Se tekee vain pieni määrä järkeä ensimmäinen kerta kun näet sen, mutta tässä se menee:
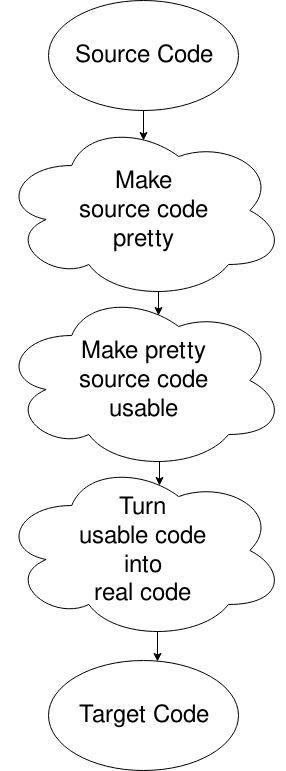
Hups, väärä kaavio, mutta tämä tulee tehdä. Pohjimmiltaan, voit saada lähde-tiedoston, sinun laita se muotoon, että tietokone haluaa (poistamalla valkoinen tila ja sen sellaista), muuttaa se joksikin, tietokone voi liikkua hyvin, ja sitten tuottaa koodin, joka. Siinä on muutakin. Se on toista kertaa tai omaa tutkimusta varten, jos uteliaisuus tappaa.,
Leksikaalinen Analyysi
AKA ”Making lähdekoodin aika”
Harkitse seuraavia täysin keksittyä kieltä, joka on pohjimmiltaan vain laskin toisistaan puolipisteillä:
// source.ect 3 + 3.2; 5.0 / 1.9; 6 * 2;tietokoneen ei tarvitse sitä kaikkea. Tilat ovat vain pikkumaisia mieliämme varten. Entä uudet linjat? Kukaan ei tarvitse niitä. Tietokone muuttaa tämän koodin, jonka näet rahakkeeksi, jota se voi käyttää lähdetiedoston sijaan., Pohjimmiltaan, se tietää, että 3 on kokonaisluku, 3.2 on float, ja + on jotain, joka toimii näiden kahden arvot. Sen enempää tietokoneen ei tarvitse pärjätä. Lexical Analyzerin tehtävä on tarjota näitä poletteja lähdeohjelman sijaan.
Miten se, että on oikeastaan aika yksinkertainen: antaa lexer (vähemmän mahtaileva kuulostava tapa sanoa lexical analyzer) tavaraa odottaa, ja sitten kertoa se, mitä tehdä, kun se näkee, että tavaraa. Näitä kutsutaan säännöiksi., Tässä on esimerkki:
int cout << "I see an integer!" << endl;Kun int tulee läpi lexer ja tämä sääntö on suoritettu, sinua tervehditään kanssa on melko ilmeinen ”näen kokonaisluku!” huutomerkki. Se ei ole, miten meidän tulee käyttää lexer, mutta se on hyödyllistä nähdä, että koodin suoritus on mielivaltainen: ei ole olemassa sääntöjä, että sinun täytyy tehdä joitakin objektin ja palauttaa sen, se on vain tavallinen vanha koodi. Voi jopa käyttää useampaa kuin yhtä linjaa ympäröimällä sitä hammasraudoilla.,
muuten, käytämme jotain nimeltä FLEX tehdä meidän lexing. Se tekee asiat aika helpoiksi, mutta mikään ei estä tekemästä ohjelmaa, joka tekee tämän itse.
saada ymmärrystä siitä, miten käytämme flex, katso tämä esimerkki:
Tämä esittelee muutamia uusia käsitteitä, joten mennään niiden yli:
%% käytetään eri osiin .Lex-tiedosto. Ensimmäinen osa on julistukset – pohjimmiltaan muuttujat tehdä lexer luettavampi., Se on myös, jossa voit tuoda, jota ympäröi %{ ja %}.
toinen osa on säännöt, jotka näimme aiemmin. Nämä ovat pohjimmiltaan suuri if else if lohko. Se suorittaa linjan pisimmän ottelun kanssa. Näin ollen, vaikka muutat järjestystä float ja int, kellukkeet on vielä ottelu, kuten matching 3 merkkiä 3.2 on enemmän kuin 1 merkki 3., Huomaa, että jos mikään näistä säännöistä ei täsmää, se menee oletussääntöön, yksinkertaisesti tulostamalla merkki standard ulos. Tämän jälkeen voit käyttää yytext viittaamaan siihen, mitä se näki vastaavan säännön.
Kolmas osa on koodi, joka on yksinkertaisesti C-tai C++ – lähdekoodia, joka on ajaa suoritus. yylex(); on funktiokutsu, joka johtaa lexeriä. Voit myös tehdä sen lukea input-tiedoston, mutta oletuksena se lukee vakiosyötettä.
Sano olet luonut nämä kaksi tiedostot source.ect ja scanner.lex., Voimme luoda C++ – ohjelmaa käyttäen flex komento (koska olet flex asennettu), sitten kääntää se alas ja input meidän lähdekoodia päästä meidän mahtava tulostaa lausuntoja. Pannaan tämä toimeen!
Hey, cool! Kirjoitat vain C++ – koodia, joka vastaa syötettä sääntöihin tehdäksesi jotain.
nyt, miten kääntäjät käyttävät tätä? Yleensä, sen sijaan, että painat jotain, jokainen sääntö palauttaa jotain-merkki! Nämä poletit voidaan määritellä kääntäjän seuraavassa osassa…,
Syntaksianalysaattori
alias ”Making pretty source code usable”
It ’ s time to have fun! Kun pääsemme tänne, alamme määritellä ohjelman rakennetta. Jäsennin on juuri antanut virta kuponkia, ja sen on vastattava elementtejä stream jotta lähdekoodi on rakenne, joka on käyttökelpoinen. Siinä käytetään grammareja, sitä mitä luultavasti näit teoriatunnilla tai kuulit oudon ystäväsi höpöttävän. Ne ovat uskomattoman voimakkaita, ja niitä on niin paljon, – mutta annan mitä sinun tarvitsee tietää typerästä jäsentämme varten.,
periaatteessa grammarit vastaavat Ei-päätteisiä symboleja johonkin terminaalin ja ei-terminaalin symbolien yhdistelmään. Terminaalit ovat puun lehtiä; muilla kuin terminaaleilla on lapsia. Älä huoli, jos siinä ei ole järkeä, koodi on luultavasti ymmärrettävämpi.
käytämme biisonigeneraattoria. Tällä kertaa Jaan tiedoston osiin selitystarkoituksessa. Ensinnäkin, ilmoitukset:
ensimmäisen osan pitäisi näyttää tutulta: olemme maahan tavaraa, jota haluamme käyttää. Sen jälkeen se menee vähän hankalammaksi.,
unioni on ”todellisen” C++ – tyypin kartoitus sille, mitä me aiomme kutsua koko tämän ohjelman ajan. Joten, kun näemme intVal, voit korvata, että oman pään kanssa int, ja kun näemme floatVal, voit korvata, että oman pään kanssa float. Näet miksi myöhemmin.
seuraavaksi päästään symboleihin. Voit jakaa näitä teidän pään liittimet ja non-terminaalit, kuten kieliopit puhuimme aiemmin. Isoilla kirjaimilla tarkoitetaan terminaaleja, joten ne eivät laajene., Lowercase tarkoittaa ei-terminaaleja, joten ne jatkavat laajentumistaan. Se on vain kokous.
jokainen ilmoitus (alkaen %) julistaa jonkin symbolin. Ensinnäkin näemme, että aloitamme ei-päätteisellä program. Sitten määrittelemme joitakin rahakkeita. <> suluissa määritellään paluuarvon tyyppi: niin INTEGER_LITERAL terminaali palauttaa intVal. SEMI terminaali ei palauta mitään., Samanlainen asia voidaan tehdä non-terminaalit käyttäen type, niin voidaan nähdä, kun määritellään exp ei-terminaali, joka palauttaa floatVal.
lopulta pääsemme edelle. Tiedämme, PEMDAS, tai mitä tahansa muuta lyhenne olet ehkä oppinut, joka kertoo sinulle muutamia yksinkertaisia priorisointisääntöjä: kerto tulee ennen lisäksi, jne. Julistamme sen oudolla tavalla. Ensinnäkin listan alempi tarkoittaa korkeampaa etuoikeutta. Toiseksi voi ihmetellä, mitä tarkoittaa., Se on liitännäisyys: aika paljon, jos olemme a op b op c, ei a ja b mene yhteen, tai ehkä b ja c? Useimmat operaattorit eivät entinen, jossa a ja b mene ensin yhdessä: se on nimeltään vasemmalle liitännäisyys. Jotkin operaattorit, kuten potenssiin korotus, tehdä päinvastoin: a^b^c odottaa, että nostat b^c sitten a^(b^c). Emme kuitenkaan käsittele sitä., Katso biisonin sivua, jos haluat lisätietoja.
Okei, en varmaan kyllästy sinulle tarpeeksi ilmoitukset, tässä on kieliopin säännöt:
Tämä on kielioppi puhuimme ennen. Jos et ole perehtynyt kieliopit, se on melko yksinkertainen: vasemmalla puolella voi muuttua tahansa asioita oikealla puolella, erotettu | (looginen or). Jos se voi mennä alas useita polkuja, se on ei-ei, me kutsumme sitä epäselvä kielioppi., Tämä ei ole epäselvä, koska meidän edelle ilmoitukset – jos haluamme muuttaa sitä niin, että plus ei ole enää vasemmalle assosiatiivisia, mutta sen sijaan se on julistettu token kuten SEMI näemme, että saamme vaihto/vähentää konflikteja. Haluatko tietää lisää? Katso, miten Bison toimii, vihje, se käyttää LR-jäsentämiseen algoritmi.
no niin exp voi tulla yksi niistä tapauksista: an INTEGER_LITERAL, FLOAT_LITERAL jne. Huomaa, että se on myös rekursiivinen, niin exp voi kääntyä kahteen exp., Näin voidaan käyttää monimutkaisia lausekkeita, kuten 1 + 2 / 3 * 5. Jokainen exp, muista palauttaa float-tyyppiä.
Mitä on sisällä suluissa on sama kuin näimme lexer: mielivaltainen C++ – koodia, mutta enemmän outoa syntaktista sokeria. Tässä tapauksessa, meillä on erityisiä muuttujia lisätään alkuun $. Muuttuja $$ on periaatteessa se, mitä palautetaan. $1 on mitä on palauttaa ensimmäisen argumentin, $2 mikä on palannut toisen, jne., By ”argumentti” en tarkoita, että osaa kieliopin sääntö: niin sääntö exp PLUS exp on väite 1 exp, väite 2 PLUS, ja väite 3 exp. Kooditoteutuksessamme lisäämme ensimmäisen ilmaisun tuloksen kolmanteen.
Lopulta, kun se tulee takaisin ylös program ei-terminaali, se tulostaa tuloksen julkilausuman. Ohjelma, tässä tapauksessa, on joukko lausuntoja, joissa lausunnot ovat ilmaus seuraa puolipisteen.
nyt kirjoitetaan koodiosa., Tämä on se, mitä oikeasti juostaan, kun käydään läpi parseri:
Okay, tästä alkaa tulla mielenkiintoista. Päätoimintomme lukee nyt ensimmäisen argumentin toimittamasta tiedostosta eikä standardista, ja lisäsimme virhekoodia. Se on melko itsestään selvä, ja kommentit tekevät hyvää työtä selittäessään, mitä on tekeillä, joten jätän sen niin harjoitus lukija selvittää tämä. Sinun tarvitsee vain tietää, että nyt olemme taas lexerissä antamassa poletteja jäsentäjälle! Here is our new lexer:
Hey, that ’ s actually smaller now!, Näemme, että tulostamisen sijaan palautamme päätesymboleita. Jotkut näistä, kuten ints ja kelluu, olemme ensimmäinen asetus arvo ennen siirtymistä (yylval on paluu arvo terminaali-symboli). Muuten, se vain antaa parser virta terminal kuponkia käyttää harkintansa mukaan.
Cool, lets run it then!
There we go-our parser prints the right values! Mutta tämä ei ole oikeastaan kääntäjä, se vain toimii C++ koodi, joka suorittaa mitä haluamme. Kääntäjäksi haluamme muuttaa tämän konekoodiksi., Sitä varten meidän on lisättävä hieman lisää…
seuraavaan kertaan asti…
tajuan nyt, että tämä postaus on paljon pidempi kuin kuvittelin, joten ajattelin lopettaa tämän tähän. Meillä on periaatteessa toimiva lexer ja parser, joten se on hyvä pysähdyspaikka.
laitoin lähdekoodin minun Github, jos olet utelias näkemään lopputuotteen. Kun julkaisuja tulee lisää, repo näkee enemmän toimintaa.,
Koska meidän lexer ja jäsennin, voimme nyt tuottaa väli-edustus meidän koodi, joka voidaan nyt muuntaa todellinen kone koodin, ja minä näytän sinulle, miten tehdä se.
lisäresursseja
Jos satut haluat lisätietoja mitään kuulu tänne, en linkittänyt juttuja, saada alkoi. Kävin paljon läpi, joten tämä on tilaisuuteni näyttää, miten sukeltaa niihin aiheisiin.
Oh, muuten, jos et pitänyt kääntäjän vaiheistani, tässä on varsinainen kaavio. Jätin silti pois symbolipöydän ja virheenkäsittelijän., Huomaa myös, että paljon kaavioita ovat erilaisia tästä, mutta tämä parhaiten osoittaa, mitä olemme huolissaan.

Vastaa