Si vous êtes un développeur, vous avez utilisé des langages de programmation. Ce sont des moyens géniaux de faire en sorte qu’un ordinateur fasse ce que vous voulez. Peut-être avez-vous même plongé profondément et programmé dans l’assemblage ou le code machine. Beaucoup ne veulent jamais revenir. Mais certains se demandent, Comment puis-je me torturer davantage en faisant plus de programmation de bas niveau? Je veux en savoir plus sur la façon dont les langages de programmation sont fabriqués!, Blague à part, écrire une nouvelle langue n’est pas aussi mauvais que cela puisse paraître, donc si vous avez même une légère curiosité, je vous suggère de rester et de voir de quoi il s’agit.
Ce post est destiné à donner une plongée simple dans la façon dont un langage de programmation peut être créé, et comment vous pouvez créer votre propre langage spécial. Peut-être même le nommer après vous-même. Qui le sait?.
je parie également que cela semble être une tâche incroyablement ardue à assumer. Ne vous inquiétez pas, car j’ai considéré cela. J’ai fait de mon mieux pour tout expliquer relativement simplement sans trop de tangentes., À la fin de ce post, vous serez en mesure de créer votre propre langage de programmation (il y aura quelques parties), mais il y a plus. Savoir ce qui se passe sous le capot vous rendra meilleur au débogage. Vous comprendrez mieux les nouveaux langages de programmation et pourquoi ils prennent les décisions qu’ils font. Vous pouvez avoir un langage de programmation nommé d’après vous, si Je ne l’ai pas mentionné auparavant. Aussi, il est vraiment amusant. Au moins pour moi.
Compilateurs et Interprètes
les langages de Programmation sont généralement de haut niveau. C’est-à-dire que vous ne regardez pas 0 et 1, ni les registres et le code d’assemblage., Mais, votre ordinateur ne comprend que 0 et 1, Il a donc besoin d’un moyen de passer de ce que vous lisez facilement à ce que la machine peut lire facilement. Cette traduction peut être effectuée par compilation ou interprétation.
la Compilation est le processus de transformation d’un fichier source entier de la langue source en une langue cible. Pour nos besoins, nous penserons à compiler à partir de votre tout nouveau langage de pointe, jusqu’au code machine exécutable.,

Mon but est de faire de la « magie » disparaître
l’Interprétation est le processus de l’exécution d’un code dans un fichier source plus ou moins directement. Je vais vous laisser penser que c’est magique pour ça.
alors, comment passer d’un langage source facile à lire à un langage cible difficile à comprendre?
Phases d’un compilateur
un compilateur peut être divisé en phases de différentes manières, mais il y a une façon qui est la plus courante., Cela n’a qu’un petit sens la première fois que vous le voyez, mais voilà:
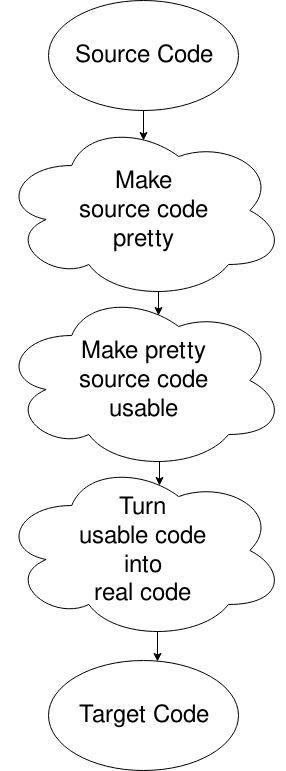
Oups, j’ai choisi le mauvais diagramme, mais cela fera l’affaire. Fondamentalement, vous obtenez le fichier source, vous le mettez dans un format que l’ordinateur Veut (en supprimant les espaces blancs et des choses comme ça), le changez en quelque chose dans lequel l’ordinateur peut bien se déplacer, puis générez le code à partir de cela. Il y a plus à cela. C’est pour une autre fois, ou pour vos propres recherches si votre curiosité vous tue.,
analyse lexicale
AKA « rendre le code source joli »
considérez le langage complètement composé suivant qui est essentiellement juste une calculatrice avec des points-virgules:
// source.ect 3 + 3.2; 5.0 / 1.9; 6 * 2;e ça. Les espaces ne sont que pour nos petits esprits. Et de nouvelles lignes? Personne n’a besoin de ces. L’ordinateur transforme ce code que vous voyez en un flux de jetons qu’il peut utiliser à la place du fichier source., Fondamentalement, il sait qu’3est un entier,3.2est un float, et+est quelque chose qui fonctionne sur ces deux valeurs. C’est tout l’ordinateur a vraiment besoin pour s’en sortir. C’est le travail de l’analyseur lexical de fournir ces jetons au lieu d’un programme source.
comment cela se passe est vraiment assez simple: donnez au lexer (une façon moins prétentieuse de dire lexical analyzer) des choses à attendre, puis dites-lui quoi faire quand il voit ce genre de choses. Ce sont des règles appelées., Voici un exemple:
int cout << "I see an integer!" << endl;lorsqu’un int passe par le lexer et que cette règle est exécutée, vous serez accueilli par un « je vois un entier! » exclamation. Ce n’est pas comme ça que nous utiliserons le lexer, mais il est utile de voir que l’exécution du code est arbitraire: il n’y a pas de règles que vous devez créer un objet et le retourner, c’est juste un ancien code régulier. Pouvez même utiliser plus d’une ligne en l’entourant avec des accolades.,
en passant, nous allons utiliser quelque chose appelé FLEX pour faire notre lexing. Cela rend les choses assez faciles, mais rien ne vous empêche de créer un programme qui le fait vous-même.
pour comprendre comment nous allons utiliser flex, regardez cet exemple:
cela introduit quelques nouveaux concepts, alors passons en revue:
%% est utilisé pour séparer les sections du .fichier lex. La première section est les déclarations-essentiellement des variables pour rendre le lexer plus lisible., C’est aussi là que vous importez, entouré par %{ et %}.
la deuxième partie est les règles, que nous avons vues auparavant. Ces sont essentiellement un grand if else if bloc. Il exécutera la ligne avec la plus longue correspondance. Ainsi, même si vous modifiez l’ordre du flotteur et int, les flotteurs correspondront toujours, car la correspondance de 3 caractères de 3.2 est supérieure à 1 caractère de 3., Notez que si aucune de ces règles ne correspond, elle passe à la règle par défaut, imprimant simplement le caractère à la norme. Vous pouvez ensuite utiliser yytext pour faire référence à ce qu’il a vu qui correspondait à cette règle.
la troisième partie est le code, qui est simplement le code source C ou C++ qui est exécuté lors de l’exécution. yylex(); est un appel de fonction qui exécute l’analyseur lexical. Vous pouvez également lui faire lire l’entrée d’un fichier, mais par défaut, il lit l’entrée standard.
Disons que vous avez créé ces deux fichiers source.ect et scanner.lex., Nous pouvons créer un programme C++ en utilisant la commandeflex (étant donné que vous avez installéflex), puis compilez-le et entrez notre code source pour atteindre nos instructions d’impression impressionnantes. Nous allons mettre cela en action!
Hey, cool! Vous écrivez simplement du code C++ qui correspond à l’entrée aux règles afin de faire quelque chose.
maintenant, comment les compilateurs utilisent-ils cela? Généralement, au lieu d’imprimer quelque chose, chaque règle renverra quelque chose – un jeton! Ces jetons peuvent être définis dans la partie suivante du compilateur…,
Syntax Analyzer
alias « rendre le code source assez utilisable »
Il est temps de s’amuser! Une fois arrivés ici, nous commençons à définir la structure du programme. L’analyseur reçoit juste un flux de jetons, et il doit faire correspondre les éléments de ce flux afin que le code source ait une structure utilisable. Pour ce faire, il utilise des grammaires, cette chose que vous avez probablement vue dans un cours de théorie ou entendu parler de votre ami bizarre. Ils sont incroyablement puissants, et il y a tellement de choses à faire, mais je vais juste donner ce que vous devez savoir pour notre analyseur stupide sorta.,
fondamentalement, les grammaires correspondent à des symboles non terminaux à une combinaison de symboles terminaux et non terminaux. Les terminaux sont des feuilles de l’arbre; les non-terminaux ont des enfants. Ne vous inquiétez pas si cela n’a pas de sens, le code sera probablement plus compréhensible.
nous allons utiliser un générateur d’analyseur appelé Bison. Cette fois, je vais diviser le fichier en sections à des fins d’explication. Tout d’abord, les déclarations:
la première partie devrait sembler familière: nous importons des choses que nous voulons utiliser. Après que ça devient un peu plus délicat.,
l’union est un mappage D’un « vrai » type C++ à ce que nous allons appeler tout au long de ce programme. Ainsi, quand nous voyons intVal, vous pouvez remplacer que dans votre tête avec des int, et quand nous nous voyons floatVal, vous pouvez remplacer que dans votre tête avec des float. Vous verrez pourquoi plus tard.
ensuite, nous arrivons aux symboles. Vous pouvez les diviser dans votre tête en tant que terminaux et non-terminaux, comme avec les grammaires dont nous avons parlé auparavant. Les lettres majuscules signifient des terminaux, de sorte qu’ils ne continuent pas à se développer., Minuscules signifie non-terminaux, de sorte qu’ils continuent à se développer. C’est juste de la convention.
chaque déclaration (commençant par%) déclare un symbole. Tout d’abord, nous voyons que nous commençons par un non-terminal program. Ensuite, nous définissons quelques jetons. Les crochets <> définissent le type de retour: ainsi, le terminal INTEGER_LITERAL renvoie un intVal. Le terminalSEMI ne renvoie rien., Une chose similaire peut être faite avec des non-terminaux en utilisant type, comme on peut le voir lors de la définition de exp en tant que non-terminal qui renvoie un floatVal.
enfin, nous entrons dans la priorité. Nous connaissons PEMDAS, ou tout autre Acronyme que vous avez appris, qui vous indique quelques règles de priorité simples: la multiplication vient avant l’addition, etc. Maintenant, nous déclarons cela ici d’une manière étrange. Tout d’abord, plus bas dans la liste signifie priorité plus élevée. Deuxièmement, vous pouvez vous demander ce que signifie left., C’est l’associativité: a peu près, si nous avons a op b op c, ne a et b aller ensemble, ou peut-être b et c? La plupart de nos opérateurs font le premier, où a et b vont ensemble en premier: c’est ce qu’on appelle l’associativité de gauche. Certains opérateurs, comme l’élévation à la puissance, à faire le contraire: a^b^c s’attend à ce que vous soulevez b^c puis a^(b^c). Cependant, nous ne traiterons pas de cela., Regardez la page Bison si vous voulez plus de détails.
D’accord, je vous ai probablement assez ennuyé avec des déclarations, voici les règles de grammaire:
c’est la grammaire dont nous parlions avant. Si vous n’êtes pas familier avec les grammaires, c’est assez simple: le côté gauche peut se transformer en l’une des choses du côté droit, séparées par | (logical or). S’il peut emprunter plusieurs chemins, c’est un non-non, nous appelons cela une grammaire ambiguë., Ce n’est pas ambigu à cause de nos déclarations de priorité – si nous le changeons pour que plus ne reste plus associatif mais soit déclaré comme un token comme SEMI, nous voyons que nous obtenons un conflit shift/reduce. Envie d’en savoir plus? Regardez comment fonctionne Bison, indice, il utilise un algorithme D’analyse LR.
Ok, exp peut devenir l’un de ces cas: un INTEGER_LITERAL, un FLOAT_LITERAL, etc. Remarque il est également récursive, donc exp peut se transformer en deux exp., Cela nous permet d’utiliser des expressions complexes, comme 1 + 2 / 3 * 5. Chaqueexp, rappelez-vous, renvoie un type float.
Ce Qui est à l’intérieur des crochets est le même que celui que nous avons vu avec le lexer: code C++ arbitraire, mais avec du sucre syntaxique plus étrange. Dans ce cas, nous avons des variables spéciales préfixées avec $. La variable $$ est essentiellement ce qui est retourné. $1 est-ce qui est retourné par le premier argument, $2 ce qui est retourné par la seconde, etc., Par « argument », je veux dire les parties de la règle de grammaire: donc la règle exp PLUS exp a l’argument 1 exp, argument 2 PLUS, et l’argument 3 exp. Ainsi, dans notre exécution de code, nous ajoutons le résultat de la première expression à la troisième.
enfin, une fois qu’il revient auprogram non-terminal, il affichera le résultat de l’instruction. Un programme, dans ce cas, est un tas d’instructions, où les instructions sont une expression suivie d’un point-virgule.
maintenant, écrivons la partie code., C’est ce qui sera réellement exécuté lorsque nous passerons par l’analyseur:
D’accord, cela commence à devenir intéressant. Notre fonction principale lit maintenant à partir d’un fichier fourni par le premier argument au lieu de standard in, et nous avons ajouté du code d’erreur. C’est assez explicite, et les commentaires font un bon travail d’explication de ce qui se passe, donc je vais laisser comme un exercice au lecteur pour comprendre cela. Tout ce que vous devez savoir, c’est que nous sommes maintenant de retour au lexer pour fournir les jetons à l’analyseur! Voici notre nouveau lexer:
Hé, c’est en fait plus petit maintenant!, Ce que nous voyons, c’est qu’au lieu d’imprimer, nous retournons des symboles de terminal. Certains d’entre eux, comme les ints et les flottants, nous définissons d’abord la valeur avant de continuer (yylval est la valeur de retour du symbole du terminal). En dehors de cela, il donne simplement à l’analyseur un flux de jetons de terminal à utiliser à sa discrétion.
Cool, permet de l’exécuter alors!
voilà, notre analyseur imprime les valeurs correctes! Mais ce n’est pas vraiment un compilateur, il exécute simplement du code C++ qui exécute ce que nous voulons. Pour faire un compilateur, nous voulons transformer cela en code machine., Pour ce faire, nous devons en ajouter un peu plus…
Jusqu’à la prochaine fois…
je réalise maintenant que ce post sera beaucoup plus long que je ne l’imaginais, alors j’ai pensé que je terminerais celui-ci ici. Nous avons essentiellement un lexer et un analyseur qui fonctionnent, c’est donc un bon point d’arrêt.
j’ai mis le code source sur mon Github, si vous êtes curieux de voir le produit final. Au fur et à mesure que plus de messages sont publiés, ce repo verra plus d’activité.,
compte tenu de notre lexer et de notre analyseur, nous pouvons maintenant générer une représentation intermédiaire de notre code qui peut être finalement convertie en vrai code machine, et je vais vous montrer exactement comment le faire.
ressources supplémentaires
Si vous voulez plus d’informations sur tout ce qui est couvert ici, j’ai lié quelques trucs pour commencer. J’y suis allé beaucoup, c’est donc ma chance de vous montrer comment plonger dans ces sujets.
Ah, au fait, si vous n’aimez pas mes phases d’un compilateur, voici un diagramme. J’ai toujours laissé la table des symboles et le gestionnaire d’erreurs., Notez également que beaucoup de diagrammes sont différents de cela, mais cela démontre le mieux ce qui nous concerne.

Laisser un commentaire