Se sei uno sviluppatore, hai usato linguaggi di programmazione. Sono modi fantastici per fare in modo che un computer faccia quello che vuoi. Forse hai anche tuffato in profondità e programmato in assemblea o codice macchina. Molti non vogliono mai tornare. Ma alcuni si chiedono, come posso torturarmi di più facendo più programmazione di basso livello? Voglio sapere di più su come sono fatti i linguaggi di programmazione!, Scherzi a parte, scrivere una nuova lingua non è così male come sembra, quindi se hai anche una leggera curiosità, ti suggerirei di restare e vedere di cosa si tratta.
Questo post ha lo scopo di dare un semplice tuffo in come un linguaggio di programmazione può essere fatto, e come si può fare il proprio linguaggio speciale. Forse anche il nome dopo te stesso. Chi lo sa.
Scommetto anche che questo sembra un compito incredibilmente scoraggiante da affrontare. Non ti preoccupare, perché ho considerato questo. Ho fatto del mio meglio per spiegare tutto relativamente semplicemente senza andare su troppe tangenti., Entro la fine di questo post, sarai in grado di creare il tuo linguaggio di programmazione (ci saranno alcune parti), ma c’è di più. Sapere cosa succede sotto il cofano ti renderà migliore nel debug. Capirai meglio i nuovi linguaggi di programmazione e perché prendono le decisioni che fanno. Puoi avere un linguaggio di programmazione che prende il nome da te, se non l’avessi detto prima. Inoltre, è davvero divertente. Almeno per me.
Compilatori e interpreti
I linguaggi di programmazione sono generalmente di alto livello. Vale a dire, non stai guardando 0s e 1s, né registri e codice assembly., Ma il tuo computer capisce solo 0 e 1, quindi ha bisogno di un modo per passare da ciò che leggi facilmente a ciò che la macchina può leggere facilmente. Che la traduzione può essere fatto attraverso la compilazione o l’interpretazione.
Compilazione è il processo di trasformare un intero file sorgente della lingua di origine in una lingua di destinazione. Per i nostri scopi, penseremo a compilare dal tuo nuovo linguaggio all’avanguardia, fino al codice macchina eseguibile.,

Il mio obiettivo è far sparire la “magia”
L’interpretazione è il processo di esecuzione del codice in un file sorgente più o meno direttamente. Ti lascerò pensare che sia magia per questo.
Quindi, come si passa dalla lingua di origine facile da leggere alla lingua di destinazione difficile da capire?
Fasi di un compilatore
Un compilatore può essere suddiviso in fasi in vari modi, ma c’è un modo che è più comune., Fa solo una piccola quantità di senso la prima volta che lo vedi, ma qui va:
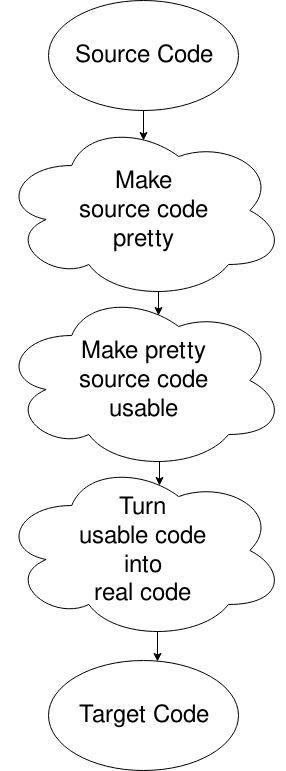
Oops, ho scelto il diagramma sbagliato, ma questo lo farà. Fondamentalmente, ottieni il file sorgente, lo metti in un formato che il computer desidera (rimuovendo lo spazio bianco e cose del genere), cambialo in qualcosa in cui il computer può muoversi bene e quindi generare il codice da quello. C’e ‘ dell’altro. Questo è per un’altra volta, o per la tua ricerca se la tua curiosità ti sta uccidendo.,
Analisi Lessicale
AKA “Rendere il codice sorgente abbastanza”
si Consideri il seguente completamente realizzato lingua che fondamentalmente solo un calcolatore con un punto e virgola:
// source.ect 3 + 3.2; 5.0 / 1.9; 6 * 2;Il computer non ha bisogno di tutto questo. Gli spazi sono solo per le nostre menti meschine. E nuove linee? Non servono a nessuno. Il computer trasforma questo codice che vedi in un flusso di token che può utilizzare al posto del file sorgente., Fondamentalmente, sa che3 è un numero intero,3.2 è un float e+ è qualcosa che opera su questi due valori. Questo è tutto ciò di cui il computer ha davvero bisogno per cavarsela. È compito dell’analizzatore lessicale fornire questi token invece di un programma sorgente.
Come funziona è davvero abbastanza semplice: dare al lexer (un modo meno pretenzioso di dire analizzatore lessicale) alcune cose da aspettarsi, quindi dirgli cosa fare quando vede quella roba. Queste sono chiamate regole., Ecco un esempio:
int cout << "I see an integer!" << endl;Quando un int passa attraverso il lexer e questa regola viene eseguita, lei sarà salutato con un abbastanza ovvio “vedo un numero intero!” esclamativo. Non è così che useremo il lexer, ma è utile vedere che l’esecuzione del codice è arbitraria: non ci sono regole che devi creare un oggetto e restituirlo, è solo un vecchio codice normale. Può anche usare più di una linea circondandola con parentesi graffe.,
A proposito, useremo qualcosa chiamato FLEX per fare il nostro lexing. Rende le cose abbastanza facili, ma nulla ti impedisce di creare un programma che lo faccia da solo.
Per capire come useremo flex, guarda questo esempio:
Questo introduce alcuni nuovi concetti, quindi esaminiamoli:
%% è usato per separare sezioni del .file lex. La prima sezione è dichiarazioni – fondamentalmente variabili per rendere il lexer più leggibile., È anche dove si importa, circondato da%{ e%}.
La seconda parte è le regole, che abbiamo visto prima. Questi sono fondamentalmente un grande bloccoifelse if. Eseguirà la linea con la partita più lunga. Pertanto, anche se si modifica l’ordine del float e int, i float corrisponderanno comunque, poiché la corrispondenza di 3 caratteri di 3.2 è superiore a 1 carattere di 3., Si noti che se nessuna di queste regole è abbinata, passa alla regola predefinita, semplicemente stampando il carattere su standard out. È quindi possibile utilizzareyytext per fare riferimento a ciò che ha visto che corrispondeva a quella regola.
Terza parte è il codice, che è semplicemente C o C++ codice sorgente che viene eseguito in esecuzione. yylex(); è una chiamata di funzione che esegue il lexer. Puoi anche farlo leggere input da un file, ma per impostazione predefinita legge da input standard.
Supponiamo che tu abbia creato questi due file come source.ectescanner.lex., Possiamo creare un programma C++ usando il comandoflex (dato che hai installatoflex), quindi compilalo e inserisci il nostro codice sorgente per raggiungere le nostre fantastiche istruzioni di stampa. Mettiamolo in azione!
Ehi, figo! Stai solo scrivendo codice C++ che corrisponde all’input delle regole per fare qualcosa.
Ora, come fanno i compilatori a usarlo? Generalmente, invece di stampare qualcosa, ogni regola restituirà qualcosa-un token! Questi token possono essere definiti nella parte successiva del compilatore…,
Syntax Analyzer
AKA “Fare abbastanza codice sorgente utilizzabile”
E ‘ il momento di divertirsi! Una volta arrivati qui, iniziamo a definire la struttura del programma. Il parser riceve solo un flusso di token e deve corrispondere agli elementi in questo flusso per rendere il codice sorgente utilizzabile. Per fare questo, usa le grammatiche, quella cosa che probabilmente hai visto in una lezione di teoria o hai sentito il tuo strano amico geeking. Sono incredibilmente potenti, e c’è così tanto da approfondire, ma darò solo ciò che devi sapere per il nostro parser muto.,
Fondamentalmente, le grammatiche corrispondono a simboli non terminali a una combinazione di simboli terminali e non terminali. I terminali sono foglie dell’albero; i non terminali hanno figli. Non preoccuparti se ciò non ha senso, il codice sarà probabilmente più comprensibile.
Useremo un generatore di parser chiamato Bison. Questa volta, dividerò il file in sezioni a scopo di spiegazione. Innanzitutto, le dichiarazioni:
La prima parte dovrebbe sembrare familiare: stiamo importando cose che vogliamo usare. Dopo di che diventa un po ‘ più difficile.,
L’unione è una mappatura di un tipo C++ “reale” a quello che lo chiameremo in tutto questo programma. Quindi, quando vediamointVal, puoi sostituirlo nella tua testa conint, e quando vediamofloatVal, puoi sostituirlo nella tua testa confloat. Capirai il perche ‘ piu ‘ tardi.
Poi arriviamo ai simboli. Puoi dividerli nella tua testa come terminali e non terminali, come con le grammatiche di cui abbiamo parlato prima. Lettere maiuscole significa terminali, quindi non continuano ad espandersi., Minuscolo significa non terminali, quindi continuano ad espandersi. E ‘ solo una convenzione.
Ogni dichiarazione (che inizia con %) dichiara alcuni simboli. Innanzitutto, vediamo che iniziamo con un non terminale program. Quindi, definiamo alcuni token. Le parentesi<> definiscono il tipo di ritorno: quindi il terminaleINTEGER_LITERAL restituisce unintVal. Il terminaleSEMI non restituisce nulla., Una cosa simile può essere fatta con i non-terminali usando type, come si può vedere quando si definisce exp come un non-terminale che restituisce un floatVal.
Finalmente entriamo in precedenza. Conosciamo i PEMDA, o qualsiasi altro acronimo che potresti aver imparato, che ti dice alcune semplici regole di precedenza: la moltiplicazione viene prima dell’aggiunta, ecc. Ora, lo dichiariamo qui in un modo strano. Innanzitutto, più in basso nell’elenco significa precedenza più alta. In secondo luogo, potresti chiederti cosa significa left., Che associatività: praticamente, se abbiamo a op b op c do a e b andare insieme, o forse b e c? La maggior parte dei nostri operatori fa il primo, dove a e b vanno insieme per primi: si chiama associatività sinistra. Alcuni operatori, come l’esponenziazione, fanno il contrario: a^b^csi aspetta che tu aumentib^cquindia^(b^c). Tuttavia, non ci occuperemo di questo., Guarda la pagina dei Bisonti se vuoi maggiori dettagli.
Ok Probabilmente ti ho annoiato abbastanza con le dichiarazioni, ecco le regole grammaticali:
Questa è la grammatica di cui stavamo parlando prima. Se non hai familiarità con le grammatiche, è piuttosto semplice: il lato sinistro può trasformarsi in una qualsiasi delle cose sul lato destro, separate con | (logico or). Se può andare su più percorsi, questo è un no-no, lo chiamiamo una grammatica ambigua., Questo non è ambiguo a causa delle nostre dichiarazioni di precedenza – se lo cambiamo in modo che plus non sia più lasciato associativo ma invece viene dichiarato come token come SEMI, vediamo che otteniamo un conflitto shift/reduce. Vuoi saperne di più? Cerca come funziona Bison, suggerimento, usa un algoritmo di analisi LR.
Va bene, quindi exppuò diventare uno di quei casi: anINTEGER_LITERAL, aFLOAT_LITERAL, ecc. Nota che è anche ricorsivo, quindi exp può trasformarsi in due exp., Questo ci permette di usare espressioni complesse, come 1 + 2 / 3 * 5. Ogni exp, ricorda, restituisce un tipo float.
Ciò che è all’interno delle parentesi è lo stesso che abbiamo visto con il lexer: codice C++ arbitrario, ma con uno zucchero sintattico più strano. In questo caso, abbiamo variabili speciali anteposte con $. La variabile $$ è fondamentalmente ciò che viene restituito. $1è ciò che viene restituito dal primo argomento,$2 ciò che viene restituito dal secondo, ecc., Per” argomento”intendo parti della regola grammaticale: quindi la regola exp PLUS exp ha argomento 1 exp, argomento 2 PLUS e argomento 3 exp. Quindi, nella nostra esecuzione di codice, aggiungiamo il risultato della prima espressione alla terza.
Infine, una volta tornato alprogram non terminale, stamperà il risultato dell’istruzione. Un programma, in questo caso, è un gruppo di istruzioni, in cui le istruzioni sono un’espressione seguita da un punto e virgola.
Ora scriviamo la parte del codice., Questo è ciò che verrà effettivamente eseguito quando passiamo attraverso il parser:
Ok, questo sta iniziando a diventare interessante. La nostra funzione principale ora legge da un file fornito dal primo argomento anziché dallo standard in, e abbiamo aggiunto del codice di errore. È piuttosto autoesplicativo, e i commenti fanno un buon lavoro nello spiegare cosa sta succedendo, quindi lo lascerò come esercizio al lettore per capirlo. Tutto quello che devi sapere è che ora siamo tornati al lexer per fornire i token al parser! Ecco il nostro nuovo lexer:
Hey, questo è in realtà più piccolo ora!, Quello che vediamo è che invece di stampare, stiamo restituendo simboli terminali. Alcuni di questi, come ints e float, stiamo prima impostando il valore prima di passare (yylval è il valore restituito del simbolo del terminale). Oltre a questo, sta solo dando al parser un flusso di token terminali da utilizzare a sua discrezione.
Cool, consente di eseguire allora!
Ci siamo – il nostro parser stampa i valori corretti! Ma questo non è davvero un compilatore, esegue solo il codice C++ che esegue ciò che vogliamo. Per creare un compilatore, vogliamo trasformarlo in codice macchina., Per farlo, dobbiamo aggiungere un po ‘ di più…
Fino alla prossima volta…
Ora mi rendo conto che questo post sarà molto più lungo di quanto immaginassi, quindi ho pensato di finirlo qui. Fondamentalmente abbiamo un lexer e un parser funzionanti, quindi è un buon punto di arresto.
Ho messo il codice sorgente sul mio Github, se sei curioso di vedere il prodotto finale. Man mano che vengono rilasciati più post, quel repository vedrà più attività.,
Dato il nostro lexer e parser, ora possiamo generare una rappresentazione intermedia del nostro codice che può essere finalmente convertito in codice macchina reale, e ti mostrerò esattamente come farlo.
Risorse aggiuntive
Se ti capita di volere maggiori informazioni su qualsiasi cosa coperta qui, ho collegato alcune cose per iniziare. Sono andato a destra su un sacco, quindi questa è la mia occasione per mostrarvi come immergersi in questi argomenti.
Oh, a proposito, se non ti piacciono le mie fasi di un compilatore, ecco un diagramma reale. Ho ancora lasciato la tabella dei simboli e il gestore degli errori., Si noti inoltre che molti diagrammi sono diversi da questo, ma questo dimostra al meglio ciò di cui ci occupiamo.

Lascia un commento