Hvis du er en utvikler, du har brukt programmeringsspråk. De er fantastiske måter å gjøre en datamaskin gjøre hva du vil ha det til. Kanskje du har selv due dyp og er programmert i forsamlingen eller maskinkode. Mange vil aldri komme tilbake. Men noen lurer på, hvordan kan jeg torturere meg selv mer ved å gjøre mer lave nivået programmering? Jeg ønsker å vite mer om hvordan programmeringsspråk som er laget!, All spøk til side, å skrive et nytt språk er ikke så ille som det høres ut, så hvis du har selv en mild nysgjerrighet, foreslår jeg at du holder deg rundt og se hva det handler om.
Dette innlegget er ment å gi en enkel dykke inn i hvordan et programmeringsspråk som kan bli gjort, og hvordan du kan lage ditt eget språk. Kanskje til og med navnet på den etter deg. Hvem vet.
jeg også satse på at dette virker som en utrolig skremmende oppgave å ta på. Ikke bekymre deg, for jeg har vurdert dette. Jeg gjorde mitt beste for å forklare alt relativt enkelt uten å gå på for mange tangenter., Ved slutten av dette innlegget, vil du være i stand til å lage dine egne programmeringsspråk (det vil være noen deler), men det er mer. Å vite hva som foregår «under panseret» vil gjøre deg bedre på feilsøking. Du vil bedre forstå nye programmeringsspråk og hvorfor de gjør de beslutninger som de gjør. Du kan ha et programmeringsspråk som er oppkalt etter deg selv, hvis jeg ikke nevne at før. Også, det er virkelig moro. I hvert fall for meg.
Kompilatorer og Tolker
programmeringsspråk er generelt høyt nivå. Det vil si at du ikke ser på 0s og 1-ere, eller registrerer og assembly-kode., Men, datamaskinen bare forstår 0s og 1-ere, så er det behov for en måte å flytte fra hva du leser lett å hva maskinen kan lese lett. Denne oversettelsen kan gjøres gjennom samling eller tolkning.
Samling er prosessen med å slå en hel kilde filen av kilden språket i en target språk. For vårt formål, vi skal tenke på å kompilere ned fra din splitter nye, state of the art språk, hele veien ned til kjørbart maskin kode.,

målet Mitt er å gjøre «magi» forsvinne
Tolkning er prosessen med å kjøre kode i en kildefil mer eller mindre direkte. Jeg skal la deg tror at det er magi for dette.
Så, hvordan kan du gå fra lett-å-lese kilde språk som er vanskelig å forstå språket?
Faser av en Kompilator
En kompilator kan være delt opp i faser på ulike måter, men det er en måte som er mest vanlig., Det gjør bare en liten mengde følelse første gang du ser det, men her går:
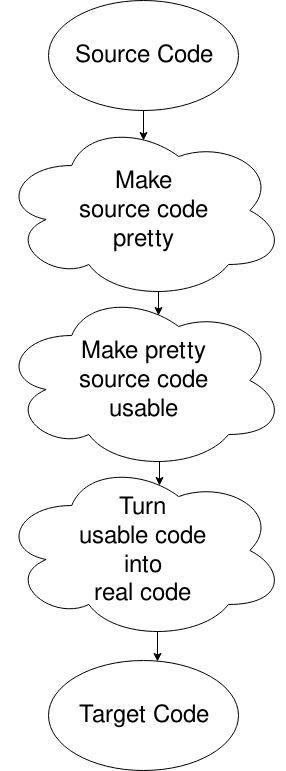
Oops, jeg plukket feil diagrammet, men dette vil gjøre. I utgangspunktet, du får kilde filen, kan du sette den inn i et format som datamaskinen vil (fjerne mellomrom og sånt), endrer det til noe datamaskinen kan flytte rundt godt i, og deretter generere kode fra det. Det er mer til det. Det er for annen gang, eller for din egen forskning om din nysgjerrighet er å drepe deg.,
Leksikalsk Analyse
AKA «å Gjøre kildekoden ganske»
bør du Vurdere følgende helt gjort opp språket som i utgangspunktet bare en kalkulator med semikolon:
// source.ect 3 + 3.2; 5.0 / 1.9; 6 * 2;datamaskinen ikke trenger alt dette. Mellomrom er bare for våre smålig sinn. Og nye linjer? Ingen trenger dem. Maskinen slår seg denne koden som du ser inn i en strøm av symboler som kan brukes i stedet for kildefilen., I utgangspunktet, det vet at 3 er et heltall, 3.2 er en dupp, og + er noe som opererer på de to verdiene. Det er alt datamaskin virkelig har behov for å få av. Det er leksikalsk analysator jobb å gi disse tokenene i stedet for en kilde programmet.
Hvordan det gjør det er egentlig ganske enkelt: gi lexer (en mindre pretensiøs klingende måte å si leksikalsk analysator) noen ting å forvente, så forteller det hva du skal gjøre når det ser at ting. Disse kalles regler., Her er et eksempel:
int cout << "I see an integer!" << endl;Når et int-objekt som kommer gjennom lexer, og denne regelen er utført, vil du bli møtt med en ganske åpenbart «jeg ser et heltall!» utropstegn. Det er ikke hvordan vi skal bruke lexer, men det er nyttig å se at kjøring av kode er tilfeldig: det er ikke regler som du har å gjøre enkelte objekt, og sende det tilbake, det er bare vanlig gamle koden. Kan også bruke mer enn én linje ved å omgi det med tannregulering.,
forresten, vil vi bruke noe som heter FLEX for å gjøre vår lexing. Det gjør ting ganske lett, men det er ingenting som hindrer deg fra å bare lage et program som gjør dette for deg selv.
for Å få en forståelse av hvordan vi vil bruke flex, se på dette eksempelet:
Dette introduserer et par nye konsepter, så la oss gå gjennom dem:
%% brukes for å skille deler av den .lex-fil. Den første delen er erklæringer i utgangspunktet variabler for å gjøre lexer mer lesbar., Det er også der du importere, omgitt av %{ og %}.
Andre delen er reglene, som vi har sett før. Disse er i utgangspunktet en stor if else if blokker. Det vil utføre linje med den lengste kampen. Dermed, selv om du endrer rekkefølgen på flottøren og int, de flyter vil fortsatt kamp, som å matche 3 tegn av 3.2 er mer enn 1 karakter av 3., Vær oppmerksom på at hvis ingen av disse reglene er matchet, det går til standardregelen, rett og slett skriver ut tegnet til standard ut. Deretter kan du bruke yytext for å se hva det var som matchet at regelen.
Tredje del er koden, som er rett og slett C eller C + + – kildekoden som kjøres på gjennomføring. yylex(); er en funksjon som samtale som går lexer. Du kan også gjøre det leses inn fra en fil, men som standard er det leser fra standard input.
Si at du har laget disse to filer som source.ect og scanner.lex., Vi kan lage en C++ – program ved hjelp av flex – kommandoen (gitt at du har flex installert), og deretter kompilere ned og innspill vår kilde kode for å nå våre awesome ut uttalelser. La oss sette dette inn i handlingen!
Hei, kult! Du bare å skrive C++ – koden som samsvarer med innspill til reglene for å gjøre noe.
Nå, hvordan kompilatorer bruke dette? Generelt, i stedet for å skrive ut noe, hver regel vil gå tilbake til noe – en token! Disse poletter kan være definert i den neste delen av kompilatoren…,
Syntaks Analyzer
AKA «Gjør pen kildekode brukbare»
Det er på tide å ha det gøy! Når vi får her, begynner vi å definere struktur i programmet. Parseren er bare gitt en strøm av symboler, og det har til kamp elementene i denne strømmen for å gjøre kildekoden har struktur som er brukbare. For å gjøre dette, bruker grammatikker, at ting du sikkert så i teorien klasse eller hørt dine rare venn geeking ut om. De er utrolig mektig, og det er så mye å gå inn, men jeg vil bare gi det du trenger å vite for våre sorta dum parser.,
i Utgangspunktet, grammatikker samsvarer ikke-terminal symboler til en kombinasjon av terminal-og ikke-terminal symboler. Terminalene er bladene på treet, ikke-terminaler har barn. Ikke bry deg om det hvis det ikke gir mening, koden vil sannsynligvis bli mer forståelig.
Vi vil bruke en parser generator kalt Bison. Denne gangen vil jeg dele filen opp i seksjoner for forklaring formål. Første, erklæringer:
Den første delen skal se ut som kjent: vi importerer ting som vi ønsker å bruke. Etter at det blir litt mer kinkig.,
The union er en kartlegging av et «ekte» C++ skriv til hva vi kommer til å kalle det hele for dette programmet. Så, når vi ser intVal, kan du erstatte det inn i hodet ditt med int, og når vi ser floatVal, kan du erstatte det inn i hodet ditt med float. Du vil se hvorfor senere.
Neste vi kommer til symboler. Du kan dele disse i hodet som terminaler og ikke-terminaler, som med grammatikker vi snakket om før. Store bokstaver betyr terminaler, slik at de ikke fortsetter å ekspandere., Små betyr ikke-terminaler, slik at de fortsetter å ekspandere. Det er bare convention.
Hver erklæring (som starter med %) erklærer noen symbol. For det første kan vi se at vi starter med en ikke-terminal program. Deretter definerer vi noen symboler. <> parentes definere tilbake type: så INTEGER_LITERAL terminal returnerer en intVal. SEMI terminal returnerer ingenting., En lignende ting kan gjøres med ikke-terminaler ved hjelp av type, som du kan se når du definerer exp som en ikke-terminal som returnerer en floatVal.
Endelig får vi inn forrang. Vi vet PEMDAS, eller hva andre akronym du kan ha lært, noe som forteller deg noen enkle regler forrang: multiplikasjon kommer før tilsetting, etc. Nå, vi erklærer at her på en merkelig måte. Første, nederst i listen betyr høyere prioritet. Andre, lurer du kanskje på hva left betyr., Det er assosiativitet: ganske mye, hvis vi har a op b op c, gjør a og b gå sammen, eller kanskje b og c? De fleste av våre operatører gjøre det tidligere, der a og b gå sammen for første: det er kalt til venstre assosiativitet. Noen operatører, som exponentiation, gjør det motsatte: a^b^c forventer at du heve b^c så a^(b^c). Vi vil imidlertid ikke takle det., Se på Bison-side hvis du vil ha flere detaljer.
Okay jeg sikkert lei deg nok med erklæringer, her er de grammatiske reglene:
Dette er grammatikken vi snakket om før. Hvis du ikke er kjent med grammatikker, det er ganske enkelt: venstre side kan slå inn i noen av tingene som er på høyre side, adskilt med | (logisk or). Hvis det kan gå ned flere stier, som er et nei-nei, vi kaller det en tvetydig grammatikk., Dette er ikke entydige på grunn av vår forrang erklæringer – hvis vi endre det slik at pluss ikke lenger er venstre-assosiative, men i stedet er erklært som en token som SEMI, ser vi at vi får et skift/redusere konflikt. Ønsker du å vite mer? Se opp hvordan Bison fungerer, hint, det bruker en LR parsing algoritme.
Okay, så exp kan bli en av de tilfeller: en INTEGER_LITERAL en FLOAT_LITERAL, osv. Merk det er også rekursiv, så exp kan slå inn i to exp., Dette gir oss muligheten til å bruke komplekse uttrykk, som 1 + 2 / 3 * 5. Hver exp husk, returnerer en type float.
Hva er inni klammene er den samme som vi så med lexer: vilkårlig C++ koden, men med flere rare syntaktisk sukker. I dette tilfellet har vi spesielle variabler prepended med $. Variabelen $$ er i utgangspunktet hva som er returnert. $1 er det som er tilbake av det første argumentet, $2 hva er returnert av andre, osv., Ved «argumentet» jeg mener deler av grammatikken regelen: så regelen exp PLUS exp har argument 1 exp argumentet 2 PLUS, og argumentet 3 exp. Så, i vår kjøring av kode, og vi legger til det første uttrykket føre til tredje.
til Slutt, når den kommer tilbake til program ikke-terminal, vil den skrive ut resultatet av uttalelsen. Et program, i dette tilfellet, er en haug av uttalelser, der uttalelser er et uttrykk som følges av et semikolon.
la oss Nå skrive koden del., Dette er hva som faktisk vil bli kjørt når vi går gjennom parser:
Ok, dette begynner å bli interessant. Vår viktigste funksjonen leser nå fra en fil som er gitt av det første argumentet i stedet for fra standard i, og vi har lagt til noen feil-kode. Det er ganske selvforklarende, og kommentarer gjøre en god jobb med å forklare hva som skjer, så jeg skal la det som en øvelse til leseren å finne ut av dette. Alt du trenger å vite er nå er vi tilbake til lexer å gi polletter til parser! Her er vår nye lexer:
Hei, dette er faktisk mindre nå!, Det vi ser er at i stedet for å skrive ut, vi er tilbake terminal symboler. Noen av disse, som israel.com og flyter, vi er først sette verdien før du flytter på (yylval er tilbake verdi av terminalen symbol). Annet enn det, det er bare å gi parser en strøm av terminal poletter til å bruke eget skjønn.
Kult, kan du kjøre den da!
Det går vi – vår parser ut den riktige verdier! Men dette er egentlig ikke en kompilator, det bare renner C++ kode som utfører det vi ønsker. For å lage en kompilator, ønsker vi å gjøre dette om til maskinkode., For å gjøre det, trenger vi å legge til litt mer…
Til Neste Gang…
jeg innser nå at dette innlegget vil bli mye lenger enn jeg forestilte meg, så jeg tenkte jeg skulle avslutte dette her. Vi i utgangspunktet har en fungerende lexer og parser, så det er en god stoppested.
jeg har lagt ut kildekoden på min Github, hvis du er nysgjerrig på å se det endelige produktet. Som flere innlegg er utgitt, at repo vil se mer aktivitet.,
Gitt våre lexer og parser, vi kan nå generere en mellomliggende representasjon av våre kode som kan bli endelig omgjort til ekte maskin-koden, og jeg vil vise deg nøyaktig hvordan du gjør det.
Ekstra Ressurser
Hvis du tilfeldigvis ønsker mer info på noe dekket her, har jeg knyttet noen ting for å komme i gang. Jeg gikk rett over mye, så dette er min sjanse til å vise deg hvordan du dykke inn i disse emnene.
Oh, forresten, hvis du ikke liker min faser av en kompilator, her er en faktisk diagrammet. Jeg har fortsatt til venstre ved symbol-tabellen og feilbehandleren., Merk også at en rekke diagrammer som er forskjellig fra dette, men dette viser best hva vi er opptatt med.

Legg igjen en kommentar