als je een ontwikkelaar bent, heb je programmeertalen gebruikt. Het zijn geweldige manieren om een computer te laten doen wat je wilt. Misschien heb je zelfs diep gedoken en geprogrammeerd in assemblage of machine code. Velen willen nooit meer terugkomen. Maar sommigen vragen zich af, hoe kan ik mezelf meer martelen door meer laag niveau programmeren? Ik wil meer weten over hoe programmeertalen worden gemaakt!, Alle gekheid op een stokje, het schrijven van een nieuwe taal is niet zo slecht als het klinkt, dus als je ook maar een lichte nieuwsgierigheid hebt, stel ik voor dat je blijft en kijkt waar het over gaat.
Dit bericht is bedoeld om een eenvoudige duik te geven in hoe een programmeertaal gemaakt kan worden, en hoe je je eigen speciale taal kunt maken. Misschien noem je het naar jezelf. Wie weet.
Ik wed ook dat dit een ongelooflijk ontmoedigende taak lijkt om op te nemen. Maak je geen zorgen, want Ik heb dit overwogen. Ik heb mijn best gedaan om alles relatief eenvoudig uit te leggen zonder te veel raakvlakken aan te gaan., Tegen het einde van deze post, zult u in staat zijn om uw eigen programmeertaal te maken (er zullen een paar delen), maar er is meer. Weten wat er onder de motorkap gebeurt zal je beter maken in het debuggen. Je zult nieuwe programmeertalen beter begrijpen en waarom ze de beslissingen nemen die ze nemen. Je kunt een programmeertaal naar jezelf laten vernoemen, als ik dat niet eerder heb gezegd. Het is ook heel leuk. Tenminste voor mij.
Compilers en tolken
programmeertalen zijn over het algemeen van hoog niveau. Dat wil zeggen, je kijkt niet naar 0s en 1s, noch registers en assembly code., Maar uw computer begrijpt alleen 0s en 1s, dus het heeft een manier nodig om te gaan van wat u gemakkelijk leest naar wat de machine gemakkelijk kan lezen. Die vertaling kan worden gedaan door compilatie of interpretatie.
compilatie is het proces van het omzetten van een volledig bronbestand van de brontaal in een doeltaal. Voor onze doeleinden, zullen we denken over het compileren van uw gloednieuwe, state of the art taal, helemaal tot aan runnable machine code.,

mijn doel is om de” magie ” te laten verdwijnen
interpretatie is het proces van het uitvoeren van code in een bronbestand min of meer direct. Ik zal je laten denken dat dit magie is.
dus, hoe ga je van eenvoudig te lezen brontaal naar moeilijk te begrijpen doeltaal?
fasen van een Compiler
een compiler kan op verschillende manieren opgesplitst worden in fasen, maar er is één manier die het meest voorkomt., De eerste keer dat je het ziet is het maar een klein beetje logisch, maar hier gaat het:
Oops, ik heb het verkeerde diagram gekozen, maar dit is voldoende. In principe, je krijgt het bronbestand, je zet het in een formaat dat de computer wil (het verwijderen van witruimte en dat soort dingen), verander het in iets waar de computer goed in kan bewegen, en dan de code daaruit genereren. Er is meer aan de hand. Dat is voor een andere keer, of voor je eigen onderzoek als je nieuwsgierigheid je doodt.,
Lexical Analysis
AKA”Making source code pretty”
beschouw de volgende volledig verzonnen taal die in feite slechts een rekenmachine is met puntkomma ‘s:
// source.ect 3 + 3.2; 5.0 / 1.9; 6 * 2;de computer heeft dat niet allemaal nodig. Ruimtes zijn alleen voor onze bekrompen geesten. En nieuwe regels? Niemand heeft die nodig. De computer zet deze code die je ziet in een stroom van tokens die het kan gebruiken in plaats van het bronbestand., In principe weet het dat 3 een geheel getal is, 3.2 een float is, en + iets is dat op deze twee waarden werkt. Dat is alles wat de computer echt nodig heeft om rond te komen. Het is de taak van de lexical analyzer om deze tokens te leveren in plaats van een bronprogramma.
hoe het dat doet is eigenlijk heel eenvoudig: geef de lexer (een minder pretentieuze manier om lexical analyzer te zeggen) wat te verwachten, vertel het dan wat te doen als het dat ziet. Dit zijn regels., Hier is een voorbeeld:
int cout << "I see an integer!" << endl;wanneer een int door de lexer komt en deze regel wordt uitgevoerd, wordt u begroet met een vrij voor de hand liggende ” I see an integer!” uitroepteken. Dat is niet hoe we de lexer zullen gebruiken, maar het is handig om te zien dat de uitvoering van de code willekeurig is: er zijn geen regels dat je een object moet maken en retourneren, het is gewoon gewone oude code. Kan zelfs meer dan één lijn gebruiken door het omringen met beugels.,
trouwens, we zullen iets gebruiken dat FLEX heet om onze lexing te doen. Het maakt dingen vrij gemakkelijk, maar niets houdt je tegen om gewoon een programma te maken dat dit zelf doet.
om inzicht te krijgen in hoe we flex zullen gebruiken, kijk naar dit voorbeeld:
Dit introduceert een paar nieuwe concepten, dus laten we ze doornemen:
%% wordt gebruikt om secties van de te scheiden .lex file. De eerste sectie is declaraties-in principe variabelen om de lexer leesbaarder te maken., Het is ook waar u importeert, omgeven door %{ en %}.
tweede deel zijn de regels, die we eerder zagen. Dit is een grootifelse if blok. Het zal de lijn uit te voeren met de langste wedstrijd. Dus, zelfs als je de volgorde van de float en int wijzigt, zullen de floats nog steeds overeenkomen, aangezien overeenkomende 3 Karakters van 3.2 meer dan 1 karakter van 3is., Merk op dat als geen van deze regels overeenkomen, het gaat om de standaardregel, gewoon afdrukken van het teken naar standaard uit. U kunt dan yytext gebruiken om te verwijzen naar wat het zag dat overeenkwam met die regel.
derde deel is de code, die gewoon C of C++ broncode is die wordt uitgevoerd. yylex(); is een functie aanroep die de lexer draait. U kunt het ook invoer uit een bestand laten lezen, maar standaard leest het van standaardinvoer.
stel dat u deze twee bestanden hebt aangemaakt als source.ect en scanner.lex., We kunnen een C++ programma maken met behulp van het flex commando (gegeven dat u flex geà nstalleerd hebt), compileer dat vervolgens en voer onze broncode in om onze geweldige print statements te bereiken. Laten we dit in actie brengen!
Hey, cool! Je schrijft gewoon C++ code die de invoer aan regels matcht om iets te doen.
nu, hoe gebruiken compilers dit? In het algemeen, in plaats van iets af te drukken, zal elke regel iets retourneren-een token! Deze tokens kunnen worden gedefinieerd in het volgende deel van de compiler…,
syntaxis Analyzer
AKA “making pretty source code usable”
Het is tijd om plezier te hebben! Zodra we hier zijn, beginnen we de structuur van het programma te definiëren. De parser is net gegeven een stroom van tokens, en het heeft om elementen in deze stroom te matchen om de broncode structuur die bruikbaar is. Om dit te doen, het gebruikt grammatica ‘ s, dat ding dat je waarschijnlijk zag in een theorie klas of hoorde je rare vriend geeking over. Ze zijn ongelooflijk krachtig, en er is zoveel om in te gaan, maar Ik zal gewoon geven wat je moet weten voor onze soort domme parser.,
in principe komen grammatica ‘ s overeen met niet-terminale symbolen met een combinatie van terminale en niet-terminale symbolen. Terminals zijn bladeren van de boom; niet-terminals hebben kinderen. Maak je geen zorgen als dat niet logisch is, zal de code waarschijnlijk begrijpelijker zijn.
we gebruiken een parser generator genaamd Bison. Deze keer zal ik het bestand opsplitsen in secties voor uitleg doeleinden. Ten eerste, de declaraties:
Het eerste deel zou bekend moeten lijken: we importeren dingen die we willen gebruiken. Daarna wordt het wat lastiger.,
De union is een afbeelding van een” echt ” c++ type naar wat we het in dit programma gaan noemen. Dus als we intVal zien, kun je dat in je hoofd vervangen door int, en als we floatVal zien, kun je dat in je hoofd vervangen door float. Dat zie je later wel.
vervolgens komen we bij de symbolen. Je kunt deze in je hoofd verdelen als terminals en niet-terminals, zoals bij de grammatica ‘ s waar we het eerder over hadden. Hoofdletters betekent terminals, dus ze blijven niet uitbreiden., Kleine letters betekent niet-terminals, dus ze blijven uitbreiden. Dat is gewoon conventie.
elke declaratie (beginnend met %) verklaart een symbool. Eerst zien we dat we beginnen met een niet-terminal program. Dan definiëren we enkele tokens. De<> haakjes definiëren het return type: dus deINTEGER_LITERAL terminal geeft eenintValterug. DeSEMI terminal geeft niets terug., Iets dergelijks kan worden gedaan met niet-terminals met type, zoals te zien is bij het definiëren van exp als een niet-terminal die een floatValretourneert.
eindelijk krijgen we voorrang. We kennen PEMDAS, of welk ander acroniem je ook geleerd hebt, dat je enkele eenvoudige voorrangsregels vertelt: vermenigvuldiging komt voor optellen, enz. Dat verklaren we hier op een vreemde manier. Ten eerste, lager in de lijst betekent hogere prioriteit. Ten tweede kun je je afvragen wat de betekent., Dat is associativiteit: als we a op b op c hebben, gaan a en b samen, of misschien b en c? De meeste van onze operators doen het eerste, waarbij a en b als eerste samengaan: dat wordt links associativiteit genoemd. Sommige operators, zoals exponentiation, doen het tegenovergestelde: a^b^c verwacht dat u b^c dan a^(b^c)verhoogt. Maar daar gaan we niet mee om., Kijk op de Bizonpagina als je meer details wilt.
Oké ik heb je waarschijnlijk genoeg verveeld met declaraties, hier zijn de grammatica regels:
Dit is de grammatica waar we het eerder over hadden. Als u niet bekend bent met grammatica ‘ s, is het vrij eenvoudig: de linkerkant kan veranderen in een van de dingen aan de rechterkant, gescheiden met | (logische or). Als het meerdere paden kan bewandelen, dan is dat een nee-nee, we noemen dat een dubbelzinnige grammatica., Dit is niet dubbelzinnig vanwege onze voorrangsverklaringen – als we het veranderen zodat plus niet langer associatief is, maar in plaats daarvan wordt verklaard als een token zoals SEMI, zien we dat we een shift/reduce conflict krijgen. Meer weten? Zoek op hoe Bizon werkt, hint, Het maakt gebruik van een LR parsing algoritme.
Oké, dus exp kan een van die gevallen worden: an INTEGER_LITERAL, a FLOAT_LITERAL, enz. Merk op dat het ook recursief is, dus exp kan veranderen in twee exp., Hierdoor kunnen we complexe expressies gebruiken, zoals 1 + 2 / 3 * 5. Elke exp, onthoud, geeft een float type terug.
wat zich binnen de haakjes bevindt is hetzelfde als we zagen met de Lexer: arbitraire C++ code, maar met meer vreemde syntactische suiker. In dit geval hebben we speciale variabelen met $. De variabele $$ is in principe wat wordt geretourneerd. $1 is wat wordt geretourneerd door het eerste argument, $2 wat wordt geretourneerd door het tweede argument, enz., Met “argument”bedoel ik delen van de grammatica: dus de regel exp PLUS exp heeft argument 1 exp, argument 2 PLUS, en argument 3 exp. Dus, in onze code uitvoering, voegen we het resultaat van de eerste expressie toe aan de derde.
ten slotte, zodra het een back-up krijgt van de program non-terminal, zal het het resultaat van de instructie afdrukken. Een programma is in dit geval een stel statements, waarbij statements een uitdrukking zijn gevolgd door een puntkomma.
laten we nu het codegedeelte schrijven., Dit is wat daadwerkelijk zal worden uitgevoerd als we door de parser gaan:
Oké, dit begint interessant te worden. Onze hoofdfunctie leest nu van een dossier dat door het eerste argument in plaats van van standaard in wordt verstrekt, en wij voegden één of andere foutcode toe. Het is vrij vanzelfsprekend, en commentaren doen een goed werk van het uitleggen wat er aan de hand is, dus ik laat het als een oefening aan de lezer om dit uit te zoeken. Alles wat je moet weten is nu we terug naar de lexer om de tokens aan de parser! Hier is onze nieuwe lexer:
Hey, dat is eigenlijk kleiner nu!, Wat we zien is dat we in plaats van af te drukken, terminalsymbolen teruggeven. Sommige van deze, zoals ints en floats, stellen we eerst de waarde in voordat we verder gaan (yylval is de retourwaarde van het terminal symbool). Anders dan dat, het is gewoon het geven van de parser een stroom van terminal tokens te gebruiken naar eigen goeddunken.
Cool, laten we het dan uitvoeren!
daar gaan we – onze parser drukt de juiste waarden af! Maar dit is niet echt een compiler, het draait gewoon C++ code die uitvoert wat we willen. Om een compiler te maken, willen we dit omzetten in machine code., Om dat te doen, moeten we iets meer toevoegen…
tot de volgende keer…
Ik realiseer me nu dat dit bericht veel langer zal zijn dan ik had gedacht, dus ik dacht dat ik deze hier zou beëindigen. We hebben in principe een werkende lexer en parser, dus het is een goed stoppunt.
Ik heb de broncode op mijn Github gezet, als je nieuwsgierig bent naar het uiteindelijke product. Naarmate meer berichten worden vrijgegeven, zal die repo meer activiteit zien.,
gegeven onze lexer en parser, kunnen we nu een intermediaire representatie van onze code genereren die uiteindelijk kan worden omgezet in echte machine code, en Ik zal je precies laten zien hoe je het moet doen.
extra bronnen
Als u meer informatie wilt over alles wat hier behandeld wordt, heb ik wat dingen gekoppeld om aan de slag te gaan. Ik heb er veel over gedaan, dus dit is mijn kans om je te laten zien hoe je in die onderwerpen kunt duiken.
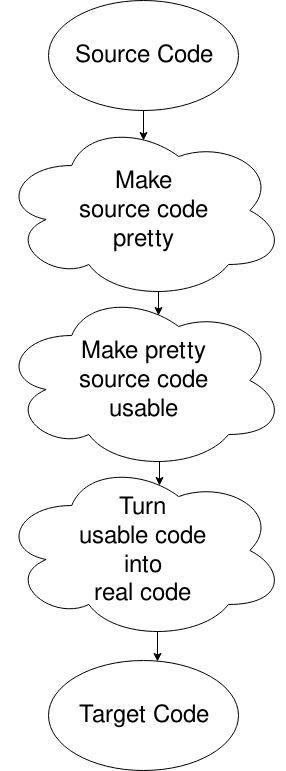
Oh, trouwens, als je mijn fasen van een compiler niet leuk vond, hier is een feitelijk diagram. Ik ben nog steeds weg van de symbooltafel en foutafhandeling., Merk ook op dat veel diagrammen anders zijn dan dit, maar dit laat het beste zien waar we mee bezig zijn.

Geef een reactie