Jeśli jesteś programistą, używasz języków programowania. To niesamowite sposoby na to, aby komputer robił to,co chcesz. Być może nawet zanurzyłeś się głęboko i zaprogramowałeś w złożeniu lub kodzie maszynowym. Wielu nigdy nie chce wrócić. Ale niektórzy zastanawiają się, jak Mogę torturować się bardziej, wykonując więcej niższego poziomu programowania? Chcę wiedzieć więcej o tym, jak powstają języki programowania!, Żarty na bok, pisanie nowego języka nie jest takie złe, jak się wydaje, więc jeśli masz choć odrobinę ciekawości, sugeruję, abyś został i zobaczył, o co chodzi.
ten post ma na celu przedstawienie prostego sposobu tworzenia języka programowania i sposobu tworzenia własnego specjalnego języka. Może nawet nazwij to po sobie. Kto wie.
założę się również, że wydaje się to niezwykle trudne zadanie do podjęcia. Nie martw się, bo rozważałem to. Zrobiłem wszystko, co w mojej mocy, aby wyjaśnić wszystko stosunkowo prosto, bez przechodzenia na zbyt wiele stycznych., Pod koniec tego postu będziesz mógł stworzyć swój własny język programowania( będzie kilka części), ale jest ich więcej. Wiedząc, co dzieje się pod maską, będziesz lepiej debugować. Będziesz lepiej rozumieć nowe języki programowania i dlaczego oni podejmują decyzje, które robią. Możesz mieć język programowania nazwany po sobie, jeśli wcześniej o tym nie wspomniałem. Poza tym, to naprawdę zabawne. Przynajmniej dla mnie.
kompilatory i Interpretatory
języki programowania są na ogół na wysokim poziomie. Oznacza to, że nie patrzysz na 0 i 1, ani na rejestry i Kod montażowy., Ale twój komputer rozumie tylko 0s i 1s, więc potrzebuje sposobu, aby przejść z tego, co czytasz łatwo, do tego, co maszyna może łatwo odczytać. Tłumaczenie może być wykonane poprzez kompilację lub interpretację.
Kompilacja jest procesem przekształcania całego pliku źródłowego języka źródłowego w język docelowy. Dla naszych celów, pomyślimy o kompilacji z twojego nowego, najnowocześniejszego języka, aż do uruchamialnego kodu maszynowego.,

moim celem jest zniknięcie „magii”
interpretacja jest procesem wykonywania kodu w pliku źródłowym mniej lub bardziej bezpośrednio. Pozwolę ci myśleć, że to magia.
jak przejść z łatwego do odczytania języka źródłowego do trudnego do zrozumienia języka docelowego?
fazy kompilatora
kompilator można podzielić na fazy na różne sposoby, ale jest jeden sposób, który jest najczęściej spotykany., To ma tylko mały sens, gdy widzisz go po raz pierwszy, ale tutaj to idzie:
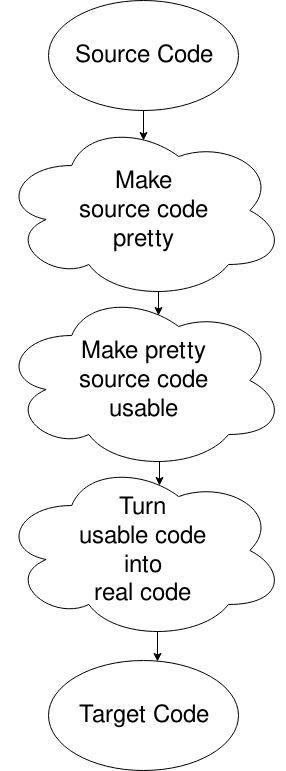
UPS, wybrałem zły diagram, ale to wystarczy. Zasadniczo dostajesz plik źródłowy, umieszczasz go w formacie, który chce komputer (usuwając białe spacje i takie tam), zmieniasz go w coś, w czym komputer może się dobrze poruszać, a następnie generujesz kod z tego. To nie wszystko. To na inny czas, lub dla własnych badań, jeśli twoja ciekawość cię zabija.,
Analiza leksykalna
AKA „upiększanie kodu źródłowego”
rozważ następujący całkowicie zmyślony język, który jest w zasadzie tylko kalkulatorem ze średnikami:
// source.ect 3 + 3.2; 5.0 / 1.9; 6 * 2;komputer nie potrzebuje wszystkich tego. Przestrzenie są tylko dla naszych małostkowych umysłów. A nowe linie? Nikt ich nie potrzebuje. Komputer zamienia ten kod, który widzisz w strumień tokenów, które może użyć zamiast pliku źródłowego., Zasadniczo wie, że 3 jest liczbą całkowitą, 3.2 jest zmiennoprzecinkowym, a + jest czymś, co działa na tych dwóch wartościach. To wszystko, czego potrzebuje komputer. Zadaniem analizatora leksykalnego jest dostarczenie tych tokenów zamiast programu źródłowego.
Jak to robi, jest to naprawdę dość proste: daj lexerowi (mniej pretensjonalnie brzmiący sposób mówienia analizatora leksykalnego) kilka rzeczy, których możesz się spodziewać, a następnie powiedz mu, co robić, gdy zobaczy te rzeczy. To się nazywa Zasady., Oto przykład:
int cout << "I see an integer!" << endl;Kiedy int przechodzi przez lexer i ta reguła jest wykonywana, zostaniesz powitany dość oczywistym „widzę liczbę całkowitą!”wykrzyknik. Nie tak będziemy używać lexera, ale warto zobaczyć, że wykonanie kodu jest dowolne: nie ma reguł, że trzeba zrobić jakiś obiekt i zwrócić go, to tylko zwykły stary kod. Może nawet używać więcej niż jednej linii, otaczając ją szelkami.,
przy okazji, będziemy używać czegoś o nazwie FLEX do lexowania. To sprawia, że wszystko jest dość łatwe, ale nic nie powstrzymuje cię od tworzenia programu, który robi to sam.
aby zrozumieć, w jaki sposób będziemy używać flex, spójrz na ten przykład:
wprowadza to kilka nowych koncepcji, więc przejdźmy do nich:
%% jest używany do oddzielania sekcji .akta Lexa. Pierwsza sekcja to deklaracje-w zasadzie zmienne, które sprawiają, że leker jest bardziej czytelny., To także miejsce, w którym importujesz, otoczone przez %{ I %}.
druga część to zasady, które widzieliśmy wcześniej. Są to w zasadzie duże bloki if else if. Wykona linię z najdłuższym meczem. Tak więc, nawet jeśli zmienisz kolejność float i int, pływaki będą nadal pasować, ponieważ dopasowanie 3 znaków 3.2 jest więcej niż 1 znakiem 3., Zauważ, że jeśli żadna z tych reguł nie jest dopasowana, przechodzi do reguły domyślnej, po prostu wypisując znak na standardowe wyjście. Następnie możesz użyć yytext, aby odnieść się do tego, co widziało, które pasowało do tej reguły.
Trzecia część to kod, który jest po prostu kodem źródłowym C lub C++, który jest uruchamiany podczas wykonywania. yylex(); jest wywołaniem funkcji, która uruchamia leker. Można również odczytywać dane wejściowe z pliku, ale domyślnie odczytuje je ze standardowego wejścia.
Załóżmy, że utworzyłeś te dwa pliki jako source.ect I scanner.lex., Możemy utworzyć program C++ używając polecenia flex (biorąc pod uwagę, że masz zainstalowany flex), następnie skompilować go i wprowadzić nasz kod źródłowy, aby dotrzeć do naszych niesamowitych instrukcji print. Zróbmy to!
Hej, cool! Po prostu piszesz kod C++, który dopasowuje dane wejściowe do reguł, aby coś zrobić.
jak kompilatory tego używają? Ogólnie rzecz biorąc, zamiast drukować coś, każda reguła zwróci coś-żeton! Tokeny te można zdefiniować w następnej części kompilatora…,
Analizator składni
AKA „Making pretty source code usable”
Czas się zabawić! Kiedy już tu dotrzemy, zaczynamy definiować strukturę programu. Parser otrzymuje tylko strumień tokenów i musi dopasować elementy w tym strumieniu, aby kod źródłowy miał strukturę, która jest użyteczna. Aby to zrobić, używa gramatyki, tej rzeczy, którą prawdopodobnie widziałeś na zajęciach z teorii lub słyszałeś o swoim dziwnym przyjacielu. Są niewiarygodnie potężne, i jest tak wiele do zrobienia, ale dam ci to, co musisz wiedzieć dla naszego głupiego parsera.,
zasadniczo gramatyki dopasowują symbole nie-terminalowe do pewnej kombinacji symboli terminalowych i nie-terminalowych. Terminale są liśćmi drzewa; nie-terminale mają dzieci. Nie martw się, jeśli to nie ma sensu, kod będzie prawdopodobnie bardziej zrozumiały.
będziemy używać generatora parserów o nazwie Bison. Tym razem podzielę plik na sekcje dla wyjaśnienia. Po pierwsze, deklaracje:
pierwsza część powinna wyglądać znajomo: importujemy rzeczy, których chcemy użyć. Potem robi się trochę trudniej.,
Unia jest odwzorowaniem „prawdziwego” Typu C++ do tego, co będziemy nazywać w całym tym programie. Tak więc, gdy widzimy intVal, możesz zastąpić to w swojej głowie int, a gdy widzimy floatVal, możesz zastąpić to w swojej głowie float. Później się przekonasz.
następnie przechodzimy do symboli. Możesz podzielić je w swojej głowie jako terminale i nie-terminale, jak w przypadku gramatyk, o których wcześniej rozmawialiśmy. Duże litery oznaczają terminale, więc nie są one nadal rozszerzane., Małe litery oznaczają nie-terminale, więc nadal się rozwijają. To tylko konwencja.
każda deklaracja (zaczynająca się od %) deklaruje jakiś symbol. Najpierw widzimy, że zaczynamy od nie-terminala program. Następnie definiujemy niektóre tokeny. <> nawiasy definiują Typ zwracania: tak więcINTEGER_LITERAL Terminal zwracaintVal. Terminal SEMI nie zwraca nic., Podobnie można zrobić z nie-terminalami używając type, co widać podczas definiowania expjako nie-terminala, który zwraca floatVal.
W końcu wchodzimy w precedens. Znamy PEMDY, czy jakikolwiek inny akronim, którego się nauczyłeś, który mówi ci kilka prostych zasad pierwszeństwa: mnożenie jest przed dodawaniem itp. Mówimy o tym w dziwny sposób. Po pierwsze, niższy na liście oznacza wyższy priorytet. Po drugie, możesz się zastanawiać, co oznacza left., To jest Asocjacja: prawie, jeśli mamy a op b op c, do a I b iść razem, a może b I c? Większość naszych operatorów robi to pierwsze, gdzie aI b idą w parze jako pierwsze: to się nazywa Asocjacja w lewo. Niektóre operatory, takie jak wykładnik, robią odwrotnie: a^b^coczekuje, że podniesieszb^cnastępniea^(b^c). Jednak z tym się nie uporamy., Zajrzyj na stronę Bizona, jeśli chcesz więcej szczegółów.
ok chyba dość Cię nudziłem deklaracjami, oto zasady gramatyczne:
To jest gramatyka o której mówiliśmy wcześniej. Jeśli nie znasz gramatyki, jest to dość proste: lewa strona może przekształcić się w dowolną z rzeczy po prawej stronie, oddzielonych | (logiczne or). Jeśli może iść wieloma ścieżkami, jest to nie-nie, nazywamy to wieloznaczną gramatyką., Nie jest to niejednoznaczne ze względu na nasze deklaracje pierwszeństwa – jeśli zmienimy to tak, że plus nie jest już asocjacyjny, ale zamiast tego jest zadeklarowany jakotoken jakSEMI, widzimy, że otrzymujemy konflikt shift/reduce. Chcesz wiedzieć więcej? Sprawdź jak działa Bizon, podpowiedz, używa algorytmu parsowania LR.
ok, więcexp może stać się jednym z tych przypadków: anINTEGER_LITERAL, aFLOAT_LITERAL, itd. Zauważ, że jest również rekurencyjny, więc expmoże przekształcić się w dwa exp., Pozwala nam to używać złożonych wyrażeń, takich jak 1 + 2 / 3 * 5. Każdyexp zwraca typ float.
to, co znajduje się wewnątrz nawiasów, jest takie samo, jak widzieliśmy z lexerem: dowolny kod C++, ale z bardziej dziwnym cukrem składniowym. W tym przypadku mamy specjalne zmienne poprzedzone $. Zmienna $$ jest w zasadzie zwracana. $1 jest zwracane przez pierwszy argument,$2 jest zwracane przez drugi argument, itd., Przez „argument” mam na myśli części reguły gramatycznej: tak więc reguła exp PLUS exp ma argument 1 exp, argument 2 PLUS, a argument 3 exp. Tak więc w naszym wykonaniu kodu dodajemy wynik pierwszego wyrażenia do trzeciego.
wreszcie, po powrocie do program non-terminal, wyświetli wynik polecenia. Program, w tym przypadku, jest zbiorem instrukcji, gdzie wyrażenia są wyrażeniem, po którym następuje średnik.
teraz napiszmy część kodu., To właśnie zostanie uruchomione, gdy przejdziemy przez parser:
ok, zaczyna być ciekawie. Nasza główna funkcja czyta teraz z pliku dostarczonego przez pierwszy argument zamiast ze standardowego in i dodaliśmy kod błędu. Jest to dość oczywiste, a komentarze dobrze wyjaśniają, co się dzieje, więc zostawię to jako ćwiczenie dla czytelnika, aby to rozgryźć. Wszystko, co musisz wiedzieć, to teraz wracamy do lexera, aby dostarczyć tokeny do parsera! Oto nasz nowy lexer:
Hej, teraz jest już mniejszy!, Widzimy, że zamiast drukować zwracamy symbole terminali. Niektóre z nich, jak int i float, najpierw ustawiamy wartość przed przejściem dalej (yylval jest wartością zwracaną symbolu terminala). Poza tym, po prostu daje parserowi strumień tokenów terminali do użycia według własnego uznania.
fajne, no to do dzieła!
proszę bardzo-nasz parser wypisuje poprawne wartości! Ale to nie jest tak naprawdę kompilator, po prostu uruchamia kod C++, który wykonuje to, co chcemy. Aby stworzyć kompilator, chcemy przekształcić go w kod maszynowy., Aby to zrobić, musimy dodać trochę więcej…
do następnego razu…
zdaję sobie sprawę, że ten post będzie o wiele dłuższy, niż sobie wyobrażałem, więc pomyślałem, że zakończę ten tutaj. W zasadzie mamy działający lexer i parser, więc to dobry punkt zatrzymania.
umieściłem kod źródłowy na moim Githubie, jeśli jesteś ciekaw, jak wygląda finalny produkt. Jak więcej postów są publikowane, że repo będzie zobaczyć więcej aktywności.,
biorąc pod uwagę nasz lexer i parser, możemy teraz wygenerować pośrednią reprezentację naszego kodu, który można ostatecznie przekształcić w prawdziwy kod maszynowy, a ja pokażę Ci dokładnie, jak to zrobić.
dodatkowe zasoby
Jeśli zdarzy ci się, że chcesz więcej informacji na temat czegokolwiek objętego tutaj, połączyłem kilka rzeczy, aby zacząć. Dużo przeszedłem, więc to moja szansa, aby pokazać ci, jak zagłębić się w te tematy.
A tak przy okazji, jeśli nie podobał Ci się mój kompilator, Oto prawdziwy diagram. Nadal przerwałem tabelę symboli i obsługę błędów., Zauważ również, że wiele diagramów różni się od tego, ale to najlepiej pokazuje, czym się zajmujemy.

Dodaj komentarz