Se você é um desenvolvedor, você usou linguagens de programação. São maneiras incríveis de fazer um computador fazer o que você quer. Talvez tenha mergulhado profundamente e programado em código de montagem ou máquina. Muitos nunca querem voltar. Mas alguns se perguntam, Como posso torturar-me mais fazendo mais programação de baixo nível? Eu quero saber mais sobre como as linguagens de programação são feitas!, Brincadeiras à parte, escrever uma nova língua não é tão mau como parece, por isso, se tiveres alguma curiosidade, sugiro que fiques por aqui e vejas do que se trata.
Este post destina-se a dar um mergulho simples em como uma linguagem de programação pode ser feita, e como você pode fazer sua própria linguagem especial. Talvez até lhe dês o teu nome. Quem sabe.também aposto que isto parece ser uma tarefa incrivelmente difícil de assumir. Não se preocupe, já pensei nisso. Eu fiz o meu melhor para explicar tudo relativamente simplesmente sem passar por muitas tangentes., Ao final deste post, você será capaz de criar sua própria linguagem de programação (haverá algumas partes), mas há mais. Saber o que se passa debaixo do capô vai fazer-te melhor a debugging. Você vai entender melhor novas linguagens de programação e por que eles tomam as decisões que eles fazem. Você pode ter uma linguagem de programação com o seu nome, se eu não mencionei isso antes. Além disso, é muito divertido. Pelo menos para mim.
Compiladores e intérpretes
linguagens de programação são geralmente de alto nível. Ou seja, você não está olhando para 0s e 1s, nem registros e código de montagem., Mas, seu computador só compreende 0s e 1s, então ele precisa de uma maneira de se mover do que você lê facilmente para o que a máquina pode ler facilmente. Essa tradução pode ser feita através de compilação ou interpretação.
compilação é o processo de transformar um arquivo fonte inteiro da linguagem de origem em uma linguagem de destino. Para os nossos propósitos, vamos pensar em compilar a partir da sua nova e moderna linguagem, até ao código de máquina executável.,

o meu objectivo é fazer a “magia” desaparecer
A interpretação é o processo de execução do Código num ficheiro de origem mais ou menos directamente. Vou deixar-te pensar que é magia para isto.
então, como você vai da linguagem de origem fácil de ler para a língua de destino difícil de entender?
fases de um compilador
um compilador pode ser dividido em fases de várias formas, mas há uma maneira que é mais comum., Faz apenas uma pequena quantidade de sentido da primeira vez que o vê, mas aqui vai:
Oops, escolhi o diagrama errado, mas isto serve. Basicamente, você obtém o arquivo fonte, você coloca-o em um formato que o computador quer (removendo espaço branco e coisas assim), alterá-lo em algo que o computador pode se mover bem dentro, e, em seguida, gerar o código a partir disso. Há mais. Isso é para outra altura, ou para a tua própria pesquisa, Se a tua curiosidade te está a matar.,
Análise Léxica
AKA “Tornar o código-fonte muito”
Considere a seguinte totalmente feita de linguagem, que é basicamente apenas uma calculadora com ponto-e-vírgula:
// source.ect 3 + 3.2; 5.0 / 1.9; 6 * 2;O computador não precisa de tudo isso. Os espaços são apenas para as nossas mentes mesquinhas. E novas linhas? Ninguém precisa disso. O computador transforma este código que você vê em um fluxo de tokens que ele pode usar em vez do arquivo fonte., Basicamente, ele sabe que 3 é um número inteiro, 3.2 é um float, e + é algo que opera sobre esses dois valores. É tudo o que o computador precisa para sobreviver. É o trabalho do analisador lexical fornecer estas fichas em vez de um programa fonte.
Como ele faz isso é realmente muito simples: dê ao lexer (uma forma menos pretensiosa de dizer analisador lexical) algumas coisas para esperar, em seguida, diga-lhe o que fazer quando ele vê essas coisas. Chamam-se regras., Aqui está um exemplo:
int cout << "I see an integer!" << endl;Quando um int vem através do lexer e esta regra é executada, você será saudado com um óbvio “eu vejo um número inteiro!” exclamacao. Não é assim que vamos usar o lexer, mas é útil ver que a execução do código é arbitrária: não há regras que você tenha que fazer algum objeto e devolvê-lo, é apenas um código antigo normal. Pode até usar mais de uma linha rodeando-a com aparelho.,a propósito, vamos usar algo chamado FLEX para fazer o nosso laxing. Torna as coisas muito fáceis, mas nada te impede de fazer um programa que faz isto sozinho.
para obter uma compreensão de como vamos usar flex, veja este exemplo:
isto introduz alguns conceitos novos, por isso vamos passar por cima deles:
%% é usado para separar secções do .lex file. A primeira seção é declarações-basicamente variáveis para tornar a lexer mais legível., É também onde você importa, rodeado por %{e%}.
segunda parte são as regras, que vimos antes. Estes são basicamente um grande if else if bloco. Ele irá executar a linha com a mais longa correspondência. Assim, mesmo se você alterar a ordem do flutuador e do int, os flutuadores ainda irão corresponder, como coincidindo 3 caracteres de é mais de 1 caractere de 3., Note que se nenhuma destas regras for correspondida, ela vai para a regra padrão, simplesmente imprimindo o caractere para fora padrão. Você pode então usar yytext para se referir ao que viu que correspondia a essa regra.
terceira parte é o código, que é simplesmente C ou C++ código fonte que é executado em execução. é uma chamada de função que executa o lexer. Você também pode fazê-lo ler a entrada de um arquivo, mas por padrão lê a partir de entrada padrão.
Say you created these two files assource.ect andscanner.lex., Nós podemos criar um programa C++ usando o comando flex (dado que você tem flex instalado), então compile isso e digite o nosso código fonte para chegar às nossas impressionantes declarações de impressão. Vamos pôr isto em acção!hey, cool! Você está apenas escrevendo código C++ que corresponde a entrada com regras, a fim de fazer alguma coisa.
Agora, como os compiladores usam isso? Geralmente, em vez de imprimir algo, cada regra vai devolver algo-um token! Estes tokens podem ser definidos na próxima parte do compilador…,
Analisador de sintaxe
AKA “Making pretty source code usable”
It’s time to have fun! Uma vez que chegamos aqui, começamos a definir a estrutura do programa. O analisador é apenas dado um fluxo de tokens, e ele tem que combinar elementos neste fluxo, a fim de fazer o código fonte tem estrutura que é utilizável. Para fazer isso, ele usa gramáticas, aquela coisa que você provavelmente viu em uma aula de teoria ou ouviu seu amigo estranho geeking para fora sobre. Eles são incrivelmente poderosos, e há tanto para fazer, mas vou dar-te o que precisas de saber para o nosso parser Idiota.,
basicamente, as gramáticas combinam símbolos não-terminais com alguma combinação de símbolos terminais e não-terminais. Os terminais são folhas da árvore; os não-terminais têm filhos. Não se preocupe com isso se isso não fizer sentido, o código provavelmente será mais compreensível.vamos usar um gerador de analisador chamado Bison. Desta vez, vou dividir o ficheiro em secções para fins de explicação. Primeiro, as declarações:
a primeira parte deve parecer familiar: estamos importando coisas que queremos usar. Depois disso, torna-se um pouco mais complicado.,
A União é um mapeamento de um tipo” real ” de C++ para o que vamos chamá-lo ao longo deste programa. Assim, quando vemos intVal, você pode substituir em sua cabeça com int, e quando vemos floatVal, você pode substituir em sua cabeça com float. Vais ver porquê mais tarde.a seguir chegamos aos símbolos. Você pode dividir estes na sua cabeça como terminais e não terminais, como com as gramáticas que falamos antes. Letras maiúsculas significam terminais, para que não continuem a expandir-se., Minúsculas significa não-terminais, por isso continuam a expandir-se. É só uma convenção.
cada declaração (começando com %) declara algum símbolo. Primeiro, vemos que começamos com um não-terminal program. Então, definimos algumas fichas. O <> os parêntesis definem o tipo de retorno: por isso oINTEGER_LITERAL O terminal devolve umintVal. O terminal SEMI não devolve nada., A similar thing can be done with non-terminals using type, as can be seen when defining exp as a non-terminal that returns a floatVal.finalmente chegamos à precedência. Conhecemos PEMDAS, ou qualquer outro acrônimo que você possa ter aprendido, o que lhe diz algumas regras de precedência simples: a multiplicação vem antes da adição, etc. Agora, nós declaramos isso aqui de uma forma estranha. Em primeiro lugar, mais baixo na lista significa maior precedência. Em segundo lugar, você pode se perguntar o que significa o ., Que a associatividade’: muito bonito, se nós temos a op b op c, não a e b ir juntos, ou talvez b e c? A maioria de nossos operadores fazem o primeiro, onde a e b vão juntos primeiro: Isso é chamado de associatividade esquerda. Algumas operadoras, como a exponenciação, fazer o oposto: a^b^c espera que você a aumentar o b^c então a^(b^c). No entanto, não vamos lidar com isso., Olhe para a página Bison se quiser mais detalhes.
ok eu provavelmente o aborreci bastante com declarações, Aqui estão as regras da gramática:
esta é a gramática que estávamos falando antes. Se você não está familiarizado com gramáticas, é muito simples: o lado esquerdo pode se transformar em qualquer uma das coisas do lado direito, separado com | (lógico or). Se ele pode percorrer vários caminhos, isso é um Não-Não, chamamos isso de uma gramática ambígua., Isto não é ambíguo por causa de nossas declarações de precedência – se mudarmos de modo que plus não seja mais associado à esquerda, mas em vez disso é declarado como um token como SEMI, vemos que temos um conflito shift/reduce. Queres saber mais? Veja como o Bison funciona, dica, usa um algoritmo de análise LR.
ok, so exp pode tornar-se um desses casos: um INTEGER_LITERAL, um FLOAT_LITERAL, etc. Note que também é recursivo, então exp pode se transformar em doisexp., Isto nos permite usar expressões complexas, como 1 + 2 / 3 * 5. Cada exp, lembre-se, devolve um tipo flutuante.
O que está dentro dos parênteses é o mesmo que vimos com o lexer: código C++ arbitrário, mas com um açúcar sintático mais estranho. Neste caso, temos variáveis especiais pré-combinadas com$. A variável $$ é basicamente o que é devolvido. $1 é o que é retornado pelo primeiro argumento, $2 o que é retornado por segundo, etc., By “argument” I mean parts of the grammar rule: so the rule exp PLUS exp has argument 1 exp, argument 2 PLUS, and argument 3 exp. Então, em nossa execução de código, adicionamos o resultado da primeira expressão à terceira.
finalmente, uma vez que volta para o id
não-terminal, irá imprimir o resultado da declaração. Um programa, neste caso, é um monte de declarações, onde as declarações são uma expressão seguida por um ponto e vírgula.agora vamos escrever a parte do Código., Isto é o que realmente será executado quando passarmos pelo analisador:
Ok, isto está começando a ficar interessante. Nossa função principal agora lê a partir de um arquivo fornecido pelo primeiro argumento em vez de padrão em, e nós adicionamos algum código de erro. É muito auto-explicativo, e comentários fazem um bom trabalho de explicar o que está acontecendo, então eu vou deixar isso como um exercício para o leitor para descobrir isso. Tudo o que precisas de saber é que agora estamos de volta ao lexer para fornecer as fichas ao analisador! Aqui está o nosso novo lexer:
Hey, isso é realmente menor agora!, O que vemos é que em vez de imprimir, estamos devolvendo símbolos terminais. Alguns destes, como Ents e floats, estamos primeiro definindo o valor antes de seguir em frente (yylval é o valor de retorno do símbolo terminal). Para além disso, está apenas a dar ao analisador um fluxo de fichas terminais para usar à sua discrição.
Cool, vamos executá-lo então!lá vamos nós-nosso analisador imprime os valores corretos! Mas este não é realmente um compilador, ele apenas executa código C++ que executa o que nós queremos. Para fazer um compilador, queremos transformar isto em código de máquina., Para isso, precisamos de acrescentar um pouco mais…
até à próxima vez…eu estou percebendo agora que este post será muito mais longo do que eu imaginava, então eu pensei em terminar este aqui. Basicamente temos um lexer e parser a funcionar, por isso é um bom ponto de paragem.
coloquei o código fonte no meu Github, se você está curioso sobre ver o produto final. À medida que mais posts forem liberados, esse repo verá mais atividade.,
Dado o nosso lexer e analisador, agora podemos gerar uma representação intermediária do código que pode ser finalmente convertido em código de máquina real, e eu vou mostrar a você exatamente como fazê-lo.
recursos adicionais
Se você por acaso quiser mais informações sobre qualquer coisa coberta aqui, eu liguei algumas coisas para começar. Passei por muita coisa, por isso é a minha oportunidade de te mostrar como mergulhar nesses tópicos.
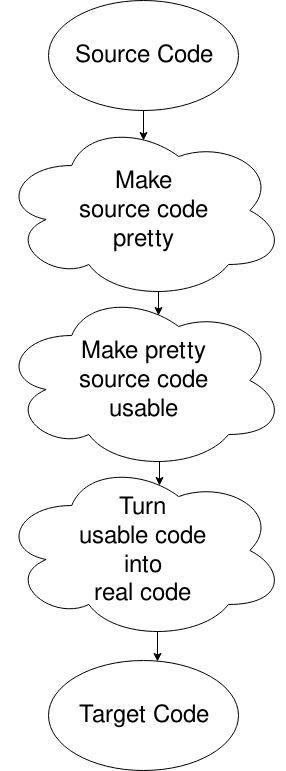
Oh, A propósito, Se você não gostou das minhas fases de um compilador, aqui está um diagrama real. Ainda deixei de fora a tabela de símbolos e o manipulador de erros., Note também que muitos diagramas são diferentes disso, mas isso demonstra melhor o que nos preocupa.

Deixe uma resposta