Dacă sunteți un dezvoltator, te-ai folosit de limbaje de programare. Sunt moduri minunate de a face un computer să facă ceea ce doriți. Poate chiar te-ai scufundat adânc și programat în asamblare sau cod mașină. Mulți nu vor să se întoarcă niciodată. Dar unii se întreabă, Cum pot să mă torturez mai mult făcând mai multă programare la nivel scăzut? Vreau să știu mai multe despre cum se fac limbajele de programare!, Lăsând gluma la o parte, scrierea unei limbi noi nu este atât de rea pe cât pare, așa că dacă ai măcar o curiozitate ușoară, ți-aș sugera să rămâi și să vezi despre ce este vorba.
această postare este menită să ofere o simplă scufundare în modul în care se poate face un limbaj de programare și cum vă puteți crea propriul limbaj special. Poate chiar numele după tine. Cine știe.de asemenea, pariez că aceasta pare o sarcină incredibil de descurajantă de preluat. Nu vă faceți griji, pentru că am luat în considerare acest lucru. Am făcut tot posibilul să explic totul relativ simplu, fără a merge pe prea multe tangente., Până la sfârșitul acestei postări, veți putea să vă creați propriul limbaj de programare (vor exista câteva părți), dar există mai multe. Știind ce se întâmplă sub capotă te va face mai bun la depanare. Veți înțelege mai bine noile limbaje de programare și de ce iau deciziile pe care le iau. Puteți avea un limbaj de programare numit după dvs., dacă nu am menționat asta înainte. De asemenea, este foarte distractiv. Cel puțin pentru mine.
compilatoare și interpreți
limbajele de Programare sunt, în general, la nivel înalt. Adică, nu te uiți la 0s și 1s, nici registrele și Codul de asamblare., Dar, computerul înțelege doar 0s și 1s, deci are nevoie de o modalitate de a trece de la ceea ce citiți cu ușurință la ceea ce mașina poate citi cu ușurință. Această traducere se poate face prin compilare sau interpretare.
compilarea este procesul de transformare a unui întreg fișier sursă al limbii sursă într-o limbă țintă. În scopurile noastre, ne vom gândi să compilăm din limbajul dvs. nou, de ultimă generație, până la codul mașinii care poate fi rulat.,

scopul Meu este de a face „magie” dispar
Interpretarea este procesul de executare de cod într-un fișier sursă mai mult sau mai puțin direct. Te las să crezi că e magic pentru asta.deci, cum treceți de la limba sursă ușor de citit la limba țintă greu de înțeles?
fazele unui compilator
un compilator poate fi împărțit în faze în diferite moduri, dar există o modalitate care este cea mai comună., Se face doar o cantitate mică de sens prima dată când îl vezi, dar aici merge:
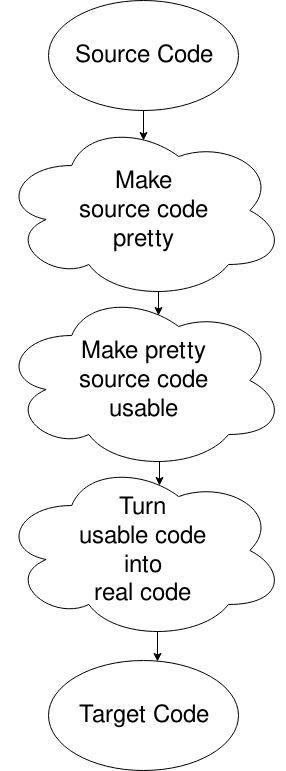
Oops, am ales diagrama greșită, dar acest lucru va face. Practic, obții fișierul sursă, îl pui într-un format pe care computerul îl dorește (eliminând spațiul alb și chestii de genul acesta), îl schimbi în ceva în care computerul se poate mișca bine și apoi generezi codul din acesta. Mai e ceva. Asta e pentru altă dată, sau pentru propria cercetare, dacă curiozitatea ta te omoară.,
analiza lexicală
AKA „efectuarea codului sursă destul de”
luați în considerare următorul limbaj complet alcătuit, care este practic doar un calculator cu punct și virgulă:
// source.ect 3 + 3.2; 5.0 / 1.9; 6 * 2; e asta. Spațiile sunt doar pentru mințile noastre mărunte. Și linii noi? Nimeni nu are nevoie de ele. Computerul transformă acest cod pe care îl vedeți într-un flux de jetoane pe care îl poate folosi în locul fișierului sursă., Practic, se știe că 3 este un număr întreg, 3.2 este un float, și + este ceva care operează pe aceste două valori. Asta e tot ce are nevoie computerul pentru a trece. Este treaba analizorului lexical să furnizeze aceste jetoane în locul unui program sursă.
cum face acest lucru este într-adevăr destul de simplu: da lexer (un mod de sondare mai puțin pretențios de a spune Analizor lexical) unele lucruri să se aștepte, apoi spune-i ce să facă atunci când vede că lucrurile. Acestea se numesc reguli., Iată un exemplu:
int cout << "I see an integer!" << endl;Cînd un int trece prin norrie și această regulă este executat, vei fi întâmpinat cu o destul de evident „văd un întreg!”exclamație. Nu așa vom folosi lexerul, dar este util să vedem că execuția codului este arbitrară: nu există reguli pe care trebuie să le faceți un obiect și să le returnați, este doar un cod vechi obișnuit. Poate folosi chiar mai mult de o linie de înconjoară-l cu bretele.,apropo, vom folosi ceva numit FLEX pentru a face lexing-ul nostru. Face lucrurile destul de ușor, dar nimic nu te oprește să faci doar un program care face asta singur.
pentru a înțelege cum vom folosi flex, uita-te la acest exemplu:
aceasta introduce câteva concepte noi, așa că să trecem peste ele:
%% este folosit pentru a separa secțiuni ale .dosarul lex. Prima secțiune este Declarații – practic variabile pentru a face lexer mai ușor de citit., Este, de asemenea, în cazul în care importați, înconjurat de %{ și %}.a doua parte este Regulile, pe care le-am văzut înainte. Acestea sunt practic un mare ifelse if bloc. Acesta va executa linia cu cel mai lung meci. Astfel, chiar dacă vă schimbați pentru a pluti și int, pluteste va potrivi în continuare, ca potrivire 3 caractere de 3.2 este mai mult de 1 caracter de 3., Rețineți că, dacă nici una dintre aceste reguli sunt potrivite, se merge la regula implicită, pur și simplu imprimarea caracterul standard afară. Puteți utiliza apoi yytext pentru a face referire la ceea ce a văzut că se potrivea cu regula respectivă.
a treia parte este codul, care este pur și simplu codul sursă C sau C++ care este rulat la execuție. yylex(); este un apel funcție care rulează lexer. Puteți face, de asemenea, citit de intrare dintr-un fișier, dar în mod implicit se citește de la intrare standard.
să presupunem că ați creat aceste două fișiere ca source.ect și scanner.lex., Putem crea un program C++ folosind flex comanda (dat ai flex instalat), apoi compila jos și introduceți codul nostru sursă pentru a ajunge nostru minunat imprima declarații. Să punem asta în acțiune!
Hei, misto! Scrii doar C++ cod care se potrivește de intrare la reguli, în scopul de a face ceva.
acum, cum compilatorii folosesc acest lucru? În general, în loc să imprimați ceva, fiecare regulă va returna ceva-un jeton! Aceste jetoane pot fi definite în următoarea parte a compilatorului…,
Syntax Analyzer
AKA „efectuarea destul de codul sursă utilizabil”
este timpul să se distreze! Odată ce ajungem aici, începem să definim structura programului. Parser este dat doar un flux de jetoane, și trebuie să se potrivească elemente în acest flux pentru a face codul sursă au structura care este utilizabil. Pentru a face acest lucru, folosește gramatici, acel lucru pe care probabil l-ai văzut într-o clasă de teorie sau L-ai auzit pe prietenul tău ciudat. Sunt incredibil de puternice, și există atât de mult pentru a merge în, dar voi da doar ceea ce trebuie să știți pentru parser nostru fel de prost.,
practic, gramaticile se potrivesc cu simbolurile non-terminale la o combinație de simboluri terminale și non-terminale. Terminalele sunt frunze de copac; non-terminale au copii. Nu vă faceți griji dacă acest lucru nu are sens, Codul va fi probabil mai ușor de înțeles.
vom folosi un generator de parser numit Bison. De data aceasta, voi împărți fișierul în secțiuni Pentru explicații. În primul rând, declarațiile:
prima parte ar trebui să pară familiară: importăm lucruri pe care vrem să le folosim. După aceea devine un pic mai complicat.,
Uniunea este o cartografiere a unui tip C++” real ” la ceea ce o vom numi pe tot parcursul acestui program. Deci, atunci când vom vedea intVal, puteți înlocui în cap cu int, și când vom vedea floatVal, puteți înlocui în cap cu float. Vei vedea de ce mai târziu.apoi ajungem la simboluri. Puteți împărți acestea în cap ca terminale și non-terminale, cum ar fi cu gramaticile despre care am vorbit înainte. Majuscule înseamnă terminale, astfel încât acestea să nu continue să se extindă., Minuscule înseamnă non-terminale, astfel încât acestea continuă să se extindă. Asta e doar convenție.fiecare declarație (începând cu %) declară un simbol. În primul rând, vedem că începem cu un non-terminal program. Apoi, definim câteva jetoane. <> paranteze defini tipul de returnare: deci INTEGER_LITERAL terminal returnează un intVal. Terminalul SEMI nu returnează nimic., Un lucru similar se poate face cu non-terminale folosind type, așa cum poate fi văzut atunci când definirea exp ca un non-terminal, care returnează un floatVal.
în cele din urmă vom ajunge în prioritate. Știm PEMDAS sau orice alt acronim pe care l-ați învățat, ceea ce vă spune câteva reguli simple de prioritate: înmulțirea vine înainte de adăugare etc. Acum, declarăm că aici într-un mod ciudat. În primul rând, mai mic în listă înseamnă prioritate mai mare. În al doilea rând, vă puteți întreba ce înseamnă left., Asta e asociativitatea: destul de mult, dacă avem a op b op c, nu a și b du-te împreună, sau poate b și c? Majoritatea operatorilor noștri fac prima, unde ași b merg împreună mai întâi: asta se numește asociativitate stângă. Unii operatori, cum ar fi exponentiala, nu invers: a^b^c așteaptă să le ridice b^c apoi a^(b^c). Cu toate acestea, nu ne vom ocupa de asta., Uită-te la pagina Bison dacă vrei mai multe detalii.bine, probabil că v-am plictisit destul cu declarații, iată regulile gramaticale:
aceasta este gramatica despre care vorbeam înainte. Dacă nu sunteți familiarizați cu gramatici, e destul de simplu: în partea stângă se pot transforma în oricare dintre lucrurile de pe partea dreaptă, separate cu | (logic or). Dacă se poate merge în jos mai multe căi, că este un NU-NU, noi numim că o gramatică ambiguă., Acest lucru nu este ambiguă din cauza noastră prioritate declarații – dacă l-am schimba, astfel încât în plus nu mai este lăsat asociativ, dar în schimb este declarat ca un token ca SEMI, vom vedea că vom obține un shift/reduce conflictele. Vrei să afli mai multe? Uită-te cum funcționează Bison, indiciu, se folosește un algoritm de parsare LR.
Bine, deci exp poate deveni unul dintre aceste cazuri: un INTEGER_LITERAL, un FLOAT_LITERAL, etc. Notă este, de asemenea, recursiv, deci exp poate transforma în două exp., Acest lucru ne permite să folosim expresii complexe, cum ar fi 1 + 2 / 3 * 5. Fiecare exp, amintiți-vă, returnează un tip float.
ceea ce este în interiorul parantezelor este același lucru pe care l-am văzut cu lexer: cod arbitrar C++, dar cu zahăr sintactic mai ciudat. În acest caz, avem variabile speciale prefixate cu $. Variabila $$ este practic ceea ce este returnat. $1este ceea ce este returnat de primul argument, $2 ceea ce este returnat de al doilea, etc., De „argument” adică părți ale regulă de gramatică: deci regula exp PLUS exp are argumentul 1 exp, argument 2 PLUS, și argumentul 3 exp. Deci, în execuția codului nostru, adăugăm rezultatul primei expresii la al treilea.în cele din urmă, odată ce acesta devine din nou până la program non-terminal, se va imprima rezultatul instrucțiunii. Un program, în acest caz, este o grămadă de declarații, unde declarațiile sunt o expresie urmată de punct și virgulă.
acum să scriem partea de cod., Aceasta este ceea ce va fi de fapt rulat atunci când vom trece prin parser:
bine, acest lucru începe să devină interesant. Funcția noastră principală citește acum dintr-un fișier furnizat de primul argument în loc de la standard in, și am adăugat un cod de eroare. Este destul de auto-explicativ, iar comentariile fac o treabă bună de a explica ce se întâmplă, așa că o voi lăsa ca un exercițiu cititorului să-și dea seama. Tot ce trebuie să știți este acum ne-am întors la lexer pentru a oferi jetoanele parser! Iată noul nostru lexer:
Hei, asta este de fapt mai mic acum!, Ceea ce vedem este că în loc să tipărim, returnăm simbolurile terminale. Unele dintre acestea, cum ar fi ints și float, setăm mai întâi valoarea înainte de a trece mai departe (yylval este valoarea returnată a simbolului terminalului). În afară de asta, îi dă parserului un flux de Jetoane terminale pe care să le folosească la discreția sa.
rece, să-l rulați atunci!
acolo mergem-parser-ul nostru imprimă valorile corecte! Dar acesta nu este cu adevărat un compilator, ci doar rulează codul C++ care execută ceea ce ne dorim. Pentru a face un compilator, vrem să transformăm acest lucru în cod mașină., Pentru a face acest lucru, trebuie să adăugăm un pic mai mult…
până data viitoare…
imi dau seama acum ca aceasta postare va fi mult mai lunga decat mi-am imaginat, asa ca m-am gandit sa termin asta aici. Avem practic un lexer de lucru și parser, deci este un bun punct de oprire.
am pus codul sursă pe Github meu, dacă sunteți curios despre a vedea produsul final. Pe măsură ce sunt lansate mai multe postări, repo va vedea mai multă activitate.,având în vedere lexerul și parser-ul nostru, putem genera acum o reprezentare intermediară a codului nostru care poate fi transformată în sfârșit în cod de mașină reală și vă voi arăta exact cum să o faceți.
resurse suplimentare
Dacă se întâmplă să doriți mai multe informații despre ceva acoperit aici, am legat câteva lucruri pentru a începe. M-am dus chiar peste o mulțime, astfel încât aceasta este șansa mea de a vă arăta cum să se scufunde în aceste subiecte.apropo, dacă nu ți-au plăcut fazele unui compilator, iată o diagramă reală. Am rămas încă de pe tabelul de simboluri și de eroare handler., De asemenea, rețineți că o mulțime de diagrame sunt diferite de aceasta, dar acest lucru demonstrează cel mai bine ceea ce ne preocupă.

Lasă un răspuns