om du är en utvecklare har du använt programmeringsspråk. De är fantastiska sätt att få en dator att göra vad du vill. Kanske har du till och med dove djupt och programmerat i montering eller maskinkod. Många vill aldrig komma tillbaka. Men vissa undrar, hur kan jag tortera mig mer genom att göra mer låg nivå programmering? Jag vill veta mer om hur programmeringsspråk görs!, Alla skämt åt sidan, skriva ett nytt språk är inte så illa som det låter, så om du har även en mild nyfikenhet, skulle jag föreslå att du stannar och se vad det handlar om.
det här inlägget är tänkt att ge ett enkelt Dyk i hur ett programmeringsspråk kan göras och hur du kan göra ditt eget speciella språk. Kanske till och med namnge det efter dig själv. Vem vet.
Jag satsar också på att det här verkar vara en otroligt skrämmande uppgift att ta på sig. Oroa dig inte, för jag har övervägt detta. Jag gjorde mitt bästa för att förklara allt relativt enkelt utan att gå på för många tangenter., I slutet av det här inlägget kommer du att kunna skapa ditt eget programmeringsspråk (det kommer att finnas några delar), men det finns mer. Att veta vad som händer under huven gör dig bättre på Felsökning. Du kommer bättre att förstå nya programmeringsspråk och varför de fattar de beslut som de gör. Du kan ha ett programmeringsspråk uppkallat efter dig själv, om jag inte nämnde det tidigare. Det är också riktigt roligt. Åtminstone för mig.
kompilatorer och tolkar
programmeringsspråk är i allmänhet hög nivå. Det vill säga, du tittar inte på 0s och 1s, eller register och monteringskod., Men, datorn förstår bara 0s och 1s, så det behöver ett sätt att flytta från vad du läser lätt till vad maskinen kan läsa lätt. Denna översättning kan göras genom sammanställning eller tolkning.
sammanställning är processen att göra en hel källfil av källspråket till ett målspråk. För våra ändamål kommer vi att tänka på att sammanställa från ditt helt nya, toppmoderna språk, hela vägen ner till runnable maskinkod.,

mitt mål är att få ”magic” att försvinna
tolkningen är processen att exekvera kod i en källfil mer eller mindre direkt. Jag låter dig tro att det är magi för det här.
Så, hur går du från lättläst källspråk till svårt att förstå målspråk?
faser av en kompilator
en kompilator kan delas upp i faser på olika sätt, men det finns ett sätt som är vanligast., Det är bara en liten känsla första gången du ser det, men här går det:
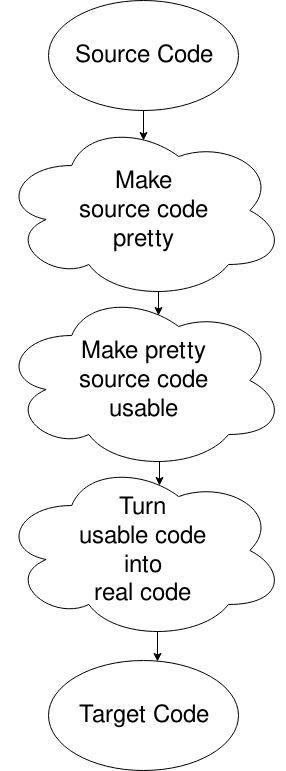
Oops, jag valde fel diagram, men det här kommer att göra. I grund och botten får du källfilen, du lägger den i ett format som datorn vill ha (ta bort vitt utrymme och sånt), ändra det till något som datorn kan röra sig bra i och sedan generera koden från det. Det finns mer att göra. Det är för en annan tid, eller för din egen forskning om din nyfikenhet dödar dig.,
Lexical Analysis
AKA ”Making source code pretty”
Tänk på följande helt uppbyggda språk som i grunden bara är en kalkylator med semikolon:
// source.ect 3 + 3.2; 5.0 / 1.9; 6 * 2;datorn behöver inte allt det. Utrymmen är bara för våra småaktiga sinnen. Och nya repliker? Ingen behöver dem. Datorn förvandlar den här koden som du ser till en ström av tokens som den kan använda istället för källfilen., I grund och botten vet den att 3 är ett heltal, 3.2 är en flottör, och + är något som fungerar på dessa två värden. Det är allt som datorn verkligen behöver klara sig. Det är den lexikala analysatorns jobb att tillhandahålla dessa tokens istället för ett källprogram.
hur det gör det är verkligen ganska enkelt: ge lexer (en mindre pretentiös klingande sätt att säga lexical analyzer) några saker att förvänta sig, sedan berätta vad man ska göra när den ser att saker. Dessa kallas regler., Här är ett exempel:
int cout << "I see an integer!" << endl;När en int kommer genom lexer och denna regel utförs, kommer du att hälsas med en ganska uppenbar ” jag ser ett heltal!” utropstecken. Det är inte så vi ska använda lexer, men det är användbart att se att kodkörningen är godtycklig: det finns inga regler som du måste göra något objekt och returnera det, det är bara vanlig gammal kod. Kan även använda mer än en linje genom att kringgå den med hängslen.,
förresten använder vi något som heter FLEX för att göra vår lexing. Det gör det ganska enkelt, men ingenting hindrar dig från att bara göra ett program som gör det själv.
för att få en förståelse för hur vi använder flex, titta på det här exemplet:
detta introducerar några nya koncept, så låt oss gå över dem:
%% används för att separera delar av .lex fil. Det första avsnittet är deklarationer-i grunden variabler för att göra lexer mer läsbar., Det är också där du importerar, omgiven av %{och%}.
andra delen är reglerna, som vi såg tidigare. Dessa är i grunden ett stort if else if – block. Det kommer att utföra linjen med den längsta matchen. Även om du ändrar flottörens och int: s ordning kommer flottören fortfarande att matcha 3 tecken i 3.2är mer än 1 tecken i 3., Observera att om ingen av dessa regler matchas, går det till standardregeln, helt enkelt skriva ut tecknet till standard ut. Du kan sedan använda yytext för att hänvisa till vad den såg som matchade den regeln.
tredje delen är koden, som helt enkelt är C eller C++ källkod som körs vid körning. yylex(); är ett funktionssamtal som kör lexer. Du kan också göra det läsa indata från en fil, men som standard läser den från standardinmatning.
säg att du skapade dessa två filer somsource.ect ochscanner.lex., Vi kan skapa ett C++ – program med kommandot flex (med tanke på att du harflex installerat) och sedan sammanställa det och mata in vår källkod för att nå våra fantastiska utskriftsutdrag. Låt oss sätta detta i handling!
hej, cool! Du skriver bara C++ – kod som matchar inmatning till regler för att göra något.
nu, Hur använder kompilatorer detta? I allmänhet, istället för att skriva ut något, kommer varje regel att returnera något-ett token! Dessa tokens kan definieras i nästa del av kompilatorn…,
Syntax Analyzer
AKA ”gör ganska källkod användbar”
det är dags att ha kul! När vi kommer hit börjar vi definiera programmets struktur. Tolken ges bara en ström av tokens, och den måste matcha element i denna ström för att få källkoden att ha struktur som är användbar. För att göra detta använder den grammatik, den där saken du förmodligen såg i en teoriklass eller hörde din konstiga vän geeking ut om. De är otroligt kraftfulla, och det finns så mycket att gå in i, men jag ska bara ge vad du behöver veta för vår sorta dum parser.,
i grund och botten matchar grammatiker icke-terminala symboler till någon kombination av terminala och icke-terminala symboler. Terminaler är löv av trädet; icke-terminaler har barn. Oroa dig inte om det inte är vettigt, koden kommer förmodligen att vara mer förståeligt.
Vi kommer att använda en tolkgenerator som heter Bison. Den här gången delar jag upp filen i sektioner för förklaringsändamål. Först deklarationerna:
den första delen ska se bekant ut: vi importerar saker som vi vill använda. Efter det blir det lite mer knepigt.,
unionen är en kartläggning av en ”riktig” C++ – typ till vad vi ska kalla det i hela det här programmet. Så när vi ser intVal kan du ersätta det i ditt huvud med int, och när vi ser floatVal kan du ersätta det i ditt huvud med float. Du får se varför senare.
nästa kommer vi till symbolerna. Du kan dela upp dessa i ditt huvud som terminaler och icke-terminaler, som med grammarerna vi pratade om tidigare. Versaler betyder terminaler, så de fortsätter inte att expandera., Små bokstäver betyder icke-terminaler, så de fortsätter att expandera. Det är bara konvent.
varje deklaration (börjar med %) deklarerar någon symbol. Först ser vi att vi börjar med en icke-terminal program. Sedan definierar vi några tokens. <> – parenteserna definierar returtypen: såINTEGER_LITERAL – terminalen returnerar enintVal. TerminalenSEMI returnerar ingenting., En liknande sak kan göras med icke-terminaler med type, vilket kan ses när du definierar exp som en icke-terminal som returnerar en floatVal.
slutligen får vi företräde. Vi vet PEMDAS, eller vad andra akronym du kanske har lärt dig, som berättar några enkla prejudikat regler: multiplikation kommer före tillägg, etc. Det förklarar vi här på ett konstigt sätt. För det första innebär lägre i listan högre prioritet. För det andra kanske du undrar vad left betyder., Det är associativitet: ganska mycket, om vi har a op b op c, gör a och b gå tillsammans, eller kanske b och c? De flesta av våra operatörer gör det förra, där a och b går ihop först: det kallas vänster associativitet. Vissa operatörer, som exponentiering, gör motsatsen: a^b^c förväntar sig att du höjer b^c sedan a^(b^c). Men vi kommer inte att ta itu med det., Titta på Bison-sidan om du vill ha mer detaljer.
Okej jag förmodligen uttråkad dig nog med deklarationer, här är grammatikreglerna:
detta är grammatiken vi pratade om tidigare. Om du inte är bekant med grammatik är det ganska enkelt: vänster sida kan förvandlas till något av sakerna på höger sida, separerade med | (logisk or). Om det kan gå ner flera vägar, det är ett nej, vi kallar det en tvetydig grammatik., Detta är inte tvetydigt på grund av våra prejudikatdeklarationer – om vi ändrar det så att plus inte längre lämnas associativt men istället förklaras som en token som SEMI ser vi att vi får ett skift/minska konflikten. Vill du veta mer? Slå upp hur Bison fungerar, hint, den använder en LR-analysalgoritm.
Okej, såexp kan bli ett av dessa fall: an INTEGER_LITERAL, a FLOAT_LITERAL, etc. Observera att det också är rekursivt, såexp kan bli tvåexp., Detta gör det möjligt för oss att använda komplexa uttryck, som 1 + 2 / 3 * 5. Varjeexp, kom ihåg, returnerar en flottörtyp.
vad som finns inuti parenteserna är detsamma som vi såg med lexer: godtycklig C++ – kod, men med mer konstigt syntaktiskt socker. I det här fallet har vi specialvariabler förinställda med $. Variabeln $$ är i princip vad som returneras. $1 är det som returneras av det första argumentet, $2 vad returneras av det andra etc., Med ”argument”menar jag delar av Grammatikregeln: så regeln exp PLUS exp har argument 1 exp, argument 2 PLUS och argument 3 exp. Så, i vår kodkörning lägger vi till det första uttrycket resultat till det tredje.
slutligen, när det kommer tillbaka tillprogram icke-terminal, kommer det att skriva ut resultatet av uttalandet. Ett program är i detta fall en massa uttalanden, där uttalanden är ett uttryck följt av en semikolon.
låt oss nu skriva koddelen., Detta är vad som faktiskt kommer att köras när vi går igenom tolken:
okej, det här börjar bli intressant. Vår huvudfunktion läser nu från en fil som tillhandahålls av det första argumentet istället för från standard in, och vi lade till en felkod. Det är ganska självförklarande, och kommentarer gör ett bra jobb med att förklara vad som händer, så jag lämnar det som en övning för läsaren att räkna ut det här. Allt du behöver veta är nu är vi tillbaka till lexer för att ge polletter till tolken! Här är vår nya lexer:
Hej, det är faktiskt mindre nu!, Vad vi ser är att vi istället för att skriva ut returnerar terminalsymboler. Några av dessa, som ints och floats, ställer vi först in värdet innan vi går vidare (yylval är terminalsymbolens returvärde). Annat än det, det är bara att ge tolken en ström av terminal tokens att använda efter eget gottfinnande.
Cool, kan köra det då!
Där går vi – vår tolk skriver ut rätt värden! Men det här är inte riktigt en kompilator, det kör bara C++ – kod som utför vad vi vill ha. För att göra en kompilator vill vi göra det till maskinkod., För att göra det måste vi lägga till lite mer…
tills nästa gång…
Jag inser nu att det här inlägget kommer att bli mycket längre än jag trodde, så jag tänkte att jag skulle avsluta den här här. Vi har i princip en fungerande lexer och parser, så det är en bra stopppunkt.
Jag har lagt källkoden på min Github, om du är nyfiken på att se slutprodukten. När fler inlägg släpps, kommer att repo se mer aktivitet.,
Med tanke på vår lexer och parser kan vi nu skapa en mellanliggande representation av vår kod som äntligen kan omvandlas till riktig maskinkod, och jag visar dig exakt hur man gör det.
ytterligare resurser
om du råkar vilja ha mer information om något som omfattas här, har jag länkat några saker för att komma igång. Jag gick över en hel del, så det här är min chans att visa dig hur man dyker in i dessa ämnen.
Åh, förresten, om du inte gillar mina faser av en kompilator, här är ett faktiskt diagram. Jag slutade fortfarande av symboltabellen och felhanteraren., Observera också att många diagram skiljer sig från detta, men det här visar bäst vad vi är oroade över.

Lämna ett svar