Nous allons maintenant revenir à l’exemple précédent de classification de 100 personnes (qui comprend 40 femmes enceintes et les 60 autres ne sont pas des femmes enceintes et des hommes avec un gros ventre) comme enceintes ou non enceintes. Sur 40 femmes enceintes 30 femmes enceintes sont correctement classés et les 10 autres femmes enceintes sont classés comme pas enceinte par l’algorithme d’apprentissage automatique. D’autre part, sur 60 personnes de la catégorie non enceinte, 55 sont classées comme non enceintes et les 5 autres sont classées comme enceintes.,
dans ce cas, TN = 55, FP = 5, FN = 10, TP = 30. La matrice de confusion est la suivante.

Quelle est la précision du modèle d’apprentissage automatique pour cette tâche de classification?,

La précision représente le nombre de classés correctement instances de données sur le nombre total d’instances de données.
Dans cet exemple, l’Exactitude = (55 + 30)/(55 + 5 + 30 + 10 ) = 0.85 et en pourcentage de la précision sera de 85%.
la précision est-elle la meilleure mesure?
La précision peut ne pas être une bonne mesure si l’ensemble de données n’est pas équilibré (les classes négative et positive ont un nombre différent d’instances de données)., Nous allons expliquer cela avec un exemple.
considérez le scénario suivant: il y a 90 personnes en bonne santé (négatives) et 10 personnes atteintes d’une maladie (positives). Maintenant, disons que notre modèle d’apprentissage automatique a parfaitement classé les 90 personnes en bonne santé, mais il a également classé les personnes malsaines en bonne santé. Que se passera-t-il dans ce scénario? Voyons la matrice de confusion et découvrons la précision?
dans cet exemple, TN = 90, FP = 0, FN = 10 et TP = 0. La matrice de confusion est la suivante.,

Précision dans ce cas sera (90 + 0)/(100) = 0.9 et en pourcentage, la précision est de 90 %.
y a-t-il quelque chose de louche?
la précision, dans ce cas, est de 90% mais ce modèle est très médiocre car les 10 personnes malsaines sont classées comme saines., Par cet exemple, ce que nous essayons de dire, c’est que la précision n’est pas une bonne mesure lorsque l’ensemble de données est déséquilibrée. L’utilisation de la précision dans de tels scénarios peut entraîner une interprétation trompeuse des résultats.
Nous allons maintenant plus loin pour trouver une autre métrique pour la classification. Encore une fois, nous revenons à l’exemple de classification de grossesse.
Maintenant, nous allons trouver la précision (valeur prédictive positive) dans la classification des instances de données., La précision est définie comme suit:
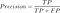
Qu’est-précision moyenne?
La précision devrait idéalement être de 1 (élevé) pour un bon Classificateur. La précision ne devient 1 que lorsque le numérateur et le dénominateur sont égaux, c’est-à-dire TP = TP +FP, cela signifie également que FP est nul. Lorsque FP augmente, la valeur du dénominateur devient supérieure au numérateur et la valeur de précision diminue (ce que nous ne voulons pas).
donc, dans l’exemple de la grossesse, la précision = 30/(30+ 5) = 0.,857
Nous allons maintenant introduire une autre mesure importante appelée rappel. Le rappel est également connu comme la sensibilité ou le taux de vrai positif et est définie comme suit:

Rappel devrait idéalement être de 1 (élevé) pour une bonne classificateur. Le rappel ne devient 1 que lorsque le numérateur et le dénominateur sont égaux, C’est-à-dire TP = TP +FN, cela signifie également que FN est nul., Lorsque FN augmente, la valeur du dénominateur devient supérieure au numérateur et la valeur de rappel diminue (ce que nous ne voulons pas).
donc, dans l’exemple de la grossesse, voyons quel sera le rappel.
rappel = 30/(30+ 10) = 0.75
donc idéalement dans un bon Classificateur, nous voulons que la précision et le rappel soient un, ce qui signifie également que FP et FN sont nuls. Par conséquent, nous avons besoin d’une métrique qui prend en compte à la fois la précision et le rappel., F1-score est une mesure qui prend en compte à la fois la précision et le rappel, et est définie comme suit:

F1 Score devient 1 uniquement lorsque la précision et le rappel sont à la fois 1. Le score F1 ne devient élevé que lorsque la précision et le rappel sont élevés. Le score F1 est la moyenne harmonique de la précision et du rappel et est une meilleure mesure que la précision.
dans l’exemple de grossesse, Score F1 = 2* ( 0.857 * 0.75)/(0.857 + 0.75) = 0.799.,
liste de lecture
ce qui suit est un article intéressant sur la métrique de classification binaire commune par neptune.ai. le lien vers l’article est disponible ici: https://neptune.ai/blog/f1-score-accuracy-roc-auc-pr-auc
Laisser un commentaire