we gaan nu terug naar het eerdere voorbeeld van het classificeren van 100 mensen (waaronder 40 zwangere vrouwen en de overige 60 zijn geen zwangere vrouwen en mannen met een dikke buik) als zwanger of niet zwanger. Van de 40 zwangere vrouwen worden 30 zwangere vrouwen correct geclassificeerd en de resterende 10 zwangere vrouwen worden geclassificeerd als niet zwanger door het machine learning-algoritme. Aan de andere kant, van de 60 mensen in de categorie niet zwanger, 55 worden geclassificeerd als niet zwanger en de overige 5 worden geclassificeerd als zwanger.,
In dit geval, TN = 55, FP = 5, FN = 10, TP = 30. De verwarring matrix is als volgt.

Wat is de nauwkeurigheid van het machine learning model voor deze classificatietaak?,

Nauwkeurigheid is het aantal correct geclassificeerde gegevens exemplaren over het totaal aantal data-exemplaren.
in dit voorbeeld, nauwkeurigheid = (55 + 30)/(55 + 5 + 30 + 10 ) = 0.85 en in percentage zal de nauwkeurigheid 85% zijn.
is nauwkeurigheid de beste maat?
nauwkeurigheid is mogelijk geen goede maatstaf als de dataset niet evenwichtig is (zowel negatieve als positieve klassen hebben een verschillend aantal gegevensinstances)., We zullen dit uitleggen met een voorbeeld.
overweeg het volgende scenario: er zijn 90 mensen die gezond zijn (negatief) en 10 mensen die een ziekte hebben (positief). Laten we zeggen dat ons machine learning model de 90 mensen perfect classificeerde als gezond, maar het classificeerde ook de ongezonde mensen als gezond. Wat zal er in dit scenario gebeuren? Laten we de verwarmingsmatrix zien en de nauwkeurigheid achterhalen?
in dit voorbeeld, TN = 90, FP = 0, Fn = 10 en TP = 0. De verwarring matrix is als volgt.,

nauwkeurigheid in dit geval zal zijn (90 + 0)/(100) = 0.9 en in percentage is de nauwkeurigheid 90%.
is er iets vreemds?
de nauwkeurigheid, in dit geval, is 90 %, maar dit model is zeer slecht omdat alle 10 mensen die ongezond zijn geclassificeerd als gezond., In dit voorbeeld proberen we te zeggen dat nauwkeurigheid geen goede maatstaf is wanneer de dataset onevenwichtig is. Het gebruik van nauwkeurigheid in dergelijke scenario ‘ s kan leiden tot misleidende interpretatie van de resultaten.
dus nu gaan we verder om een andere metriek voor classificatie te vinden. We gaan weer terug naar het voorbeeld van de zwangerschapsclassificatie.
nu zullen we de precisie (positieve voorspellende waarde) vinden in het classificeren van de data instances., Precisie wordt als volgt gedefinieerd:
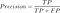
wat betekent precisie?de nauwkeurigheid van
moet idealiter 1 (hoog) zijn voor een goede classificeerder. Precisie wordt 1 alleen wanneer de teller en noemer gelijk zijn dwz TP = TP +FP, dit betekent ook dat FP nul is. Als FP verhoogt wordt de waarde van de noemer groter dan de teller en neemt de precisiewaarde af (wat we niet willen).
dus in het zwangerschapsvoorbeeld= 30/(30+ 5) = 0.,857
nu zullen we een andere belangrijke metriek introduceren, genaamd recall. Recall is ook bekend als gevoeligheid of true positive rate en wordt als volgt gedefinieerd:

recall moet idealiter 1 (hoog) zijn voor een goede classifier. Recall wordt 1 alleen wanneer de teller en noemer gelijk zijn dwz TP = TP +FN, dit betekent ook dat FN nul is., Als FN verhoogt de waarde van de noemer groter wordt dan de teller en recall waarde afneemt (die we niet willen).
dus in de zwangerschap voorbeeld laten we zien wat de recall zal zijn.
terugroepen = 30/(30+ 10) = 0.75
dus idealiter in een goede classifier, willen we dat zowel precisie als recall één zijn, wat ook betekent dat FP en FN nul zijn. Daarom hebben we een maatstaf nodig die rekening houdt met zowel precisie als terugroeping., F1-score is een gegeven die rekening houdt met zowel de precisie en recall en wordt als volgt gedefinieerd:

F1 Score wordt 1 alleen als precisie en recall zijn beide 1. De F1-score wordt alleen hoog als zowel de precisie als de recall hoog zijn. F1-score is het harmonische gemiddelde van precisie en recall en is een betere maat dan nauwkeurigheid.
in het zwangerschapsvoorbeeld, F1-Score = 2* ( 0.857 * 0.75)/(0.857 + 0.75) = 0.799.,
leeslijst
het volgende is een interessant artikel over de gemeenschappelijke binaire classificatie metriek door neptune.ai. de link naar het artikel is hier beschikbaar: https://neptune.ai/blog/f1-score-accuracy-roc-auc-pr-auc
Geef een reactie