wrócimy teraz do wcześniejszego przykładu zaklasyfikowania 100 osób (w tym 40 kobiet w ciąży, a pozostałe 60 nie jest w ciąży i mężczyzn z tłustym brzuchem) jako ciężarnych lub nie w ciąży. Na 40 kobiet w ciąży 30 kobiet w ciąży jest klasyfikowanych poprawnie, a pozostałe 10 kobiet w ciąży są klasyfikowane jako nie w ciąży przez algorytm uczenia maszynowego. Z drugiej strony, spośród 60 osób w kategorii „nie w ciąży”, 55 jest klasyfikowanych jako „nie w ciąży”, a pozostałe 5 jest klasyfikowanych jako „w ciąży”.,
w tym przypadku TN = 55, FP = 5, FN = 10, TP = 30. Macierz zamieszania jest następująca.

dokładność przedstawia liczbę poprawnie sklasyfikowanych instancji danych ponad całkowitą liczbę instancji danych. w tym przykładzie dokładność = (55 + 30)/(55 + 5 + 30 + 10 ) = 0.85 A w procentach dokładność wyniesie 85%. dokładność może nie być dobrą miarą, jeśli zbiór danych nie jest zrównoważony (zarówno ujemne, jak i dodatnie klasy mają różną liczbę instancji danych)., Wyjaśnimy to na przykładzie. rozważ następujący scenariusz: jest 90 osób, które są zdrowe (negatywne) i 10 osób, które mają jakąś chorobę (pozytywne). Teraz powiedzmy, że nasz model uczenia maszynowego doskonale sklasyfikował 90 osób jako zdrowych, ale również sklasyfikował niezdrowych ludzi jako zdrowych. Co się stanie w tym scenariuszu? Zobaczmy matrycę zamieszania i sprawdźmy dokładność? w tym przykładzie TN = 90, FP = 0, FN = 10 i TP = 0. Macierz zamieszania jest następująca., dokładność w tym przypadku będzie (90 + 0)/(100) = 0.9 A w procentach dokładność wynosi 90 %. dokładność w tym przypadku wynosi 90 % , ale ten model jest bardzo słaby, ponieważ wszystkie 10 osób, które są niezdrowe, są klasyfikowane jako zdrowe., W tym przykładzie staramy się powiedzieć, że dokładność nie jest dobrą metryką, gdy zbiór danych jest niezrównoważony. Stosowanie dokładności w takich scenariuszach może skutkować mylącą interpretacją wyników. więc teraz idziemy dalej, aby dowiedzieć się innego metryki klasyfikacji. Ponownie wracamy do przykładu klasyfikacji ciąży. teraz znajdziemy precyzję (dodatnią wartość predykcyjną) w klasyfikacji instancji danych., Precyzja jest zdefiniowana w następujący sposób:Jaka jest dokładność modelu uczenia maszynowego dla tego zadania klasyfikacyjnego?,

czy dokładność jest najlepszą miarą?

czy jest coś podejrzanego?
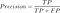
co oznacza precyzja?
precyzja powinna być idealnie równa 1 (wysoka) dla dobrego klasyfikatora. Precyzja staje się 1 tylko wtedy, gdy licznik i mianownik są równe TP = TP +FP, oznacza to również, że FP jest zero. Wraz ze wzrostem FP wartość mianownika staje się większa niż licznik, a wartość precyzji maleje(czego nie chcemy).
tak na przykładzie ciąży, precyzja = 30/(30+ 5) = 0.,857
teraz wprowadzimy kolejną ważną metrykę o nazwie recall. Przywołanie jest również znane jako czułość lub prawdziwe dodatnie tempo i jest zdefiniowane w następujący sposób:

przypomnienie powinno mieć wartość 1 (wysoką) dla dobrego klasyfikatora. Przywołanie staje się 1 tylko wtedy, gdy licznik i mianownik są równe tzn. TP = TP +FN, oznacza to również, że FN jest równe zeru., Wraz ze wzrostem wartości FN wartość mianownika staje się większa od licznika, a wartość przywoływania maleje(czego nie chcemy).
więc w przykładzie ciąży zobaczmy, co będzie przypomnieniem.
Przypomnienie = 30/(30+ 10) = 0.75
więc najlepiej w dobrym klasyfikatorze, chcemy, aby zarówno precyzja, jak i pamięć były takie, co oznacza również, że FP i FN są zerowe. Dlatego potrzebujemy metryki, która uwzględnia zarówno precyzję, jak i przypomnienie., F1-score jest metryką, która uwzględnia zarówno precyzję, jak i przypomnienie i jest zdefiniowana w następujący sposób:

wynik F1 staje się 1 tylko wtedy, gdy precyzja i przypomnienie są równe 1. Wynik F1 staje się wysoki tylko wtedy, gdy zarówno precyzja, jak i przypomnienie są wysokie. Wynik F1 jest średnią harmoniczną precyzji i przypomnienia i jest lepszą miarą niż dokładność.
na przykładzie ciąży wynik F1= 2* ( 0.857 * 0.75)/(0.857 + 0.75) = 0.799.,
lista lektur
poniżej znajduje się ciekawy artykuł na temat wspólnej klasyfikacji binarnej według neptune.ai. link do artykułu jest dostępny tutaj: https://neptune.ai/blog/f1-score-accuracy-roc-auc-pr-auc
Dodaj komentarz