Wenn Sie Entwickler sind, haben Sie Programmiersprachen verwendet. Es sind großartige Möglichkeiten, einen Computer dazu zu bringen, das zu tun, was Sie wollen. Vielleicht sind Sie sogar tief in die Montage oder den Maschinencode eingetaucht und programmiert. Viele wollen nie wiederkommen. Aber einige fragen sich, wie kann ich mich mehr quälen, indem ich mehr Low-Level-Programmierung mache? Ich möchte mehr darüber wissen, wie Programmiersprachen hergestellt werden!, Alle Scherze beiseite, eine neue Sprache zu schreiben ist nicht so schlimm, wie es klingt, also, wenn Sie sogar eine leichte Neugier haben, würde ich vorschlagen, dass Sie bleiben und sehen, worum es geht.
Dieser post ist gedacht, um geben einen einfachen Tauchen Sie ein in, wie eine Programmiersprache, die gemacht werden können, und wie können Sie machen Ihre eigenen speziellen Sprache. Vielleicht nennen Sie es sogar nach sich selbst. Wer weiß.
Ich wette auch, dass dies eine unglaublich entmutigende Aufgabe zu sein scheint. Keine Sorge, denn ich habe darüber nachgedacht. Ich habe mein Bestes getan, um alles relativ einfach zu erklären, ohne zu viele Tangenten zu machen., Am Ende dieses Beitrags können Sie Ihre eigene Programmiersprache erstellen (es wird einige Teile geben), aber es gibt noch mehr. Wenn Sie wissen, was unter der Haube vor sich geht, können Sie besser debuggen. Sie werden neue Programmiersprachen besser verstehen und warum sie die Entscheidungen treffen, die sie treffen. Sie können eine Programmiersprache nach sich selbst benannt haben, wenn ich das vorher nicht erwähnt habe. Außerdem macht es wirklich Spaß. Zumindest für mich.
Compiler und Dolmetscher
Programmiersprachen sind im Allgemeinen hochrangig. Das heißt, Sie betrachten weder 0s und 1s noch Register und Assemblycode., Ihr Computer versteht jedoch nur 0s und 1s, sodass er eine Möglichkeit benötigt, von dem, was Sie leicht lesen, zu dem zu gelangen, was die Maschine leicht lesen kann. Diese Übersetzung kann durch Zusammenstellung oder Interpretation erfolgen.
Beim Kompilieren wird eine gesamte Quelldatei der Quellsprache in eine Zielsprache umgewandelt. Für unsere Zwecke werden wir darüber nachdenken, von Ihrer brandneuen, hochmodernen Sprache bis hin zum ausführbaren Maschinencode zu kompilieren.,

Mein Ziel ist es, die“ Magie “ verschwinden zu lassen
Interpretation ist der Prozess der Ausführung von Code in einer Quelldatei mehr oder weniger direkt. Ich lasse dich denken, das ist Magie dafür.
Wie gehen Sie also von einer leicht lesbaren Ausgangssprache zur schwer verständlichen Zielsprache über?
Phasen eines Compilers
Ein Compiler kann auf verschiedene Arten in Phasen aufgeteilt werden, aber es gibt einen Weg, der am häufigsten ist., Es macht nur wenig Sinn, wenn Sie es zum ersten Mal sehen, aber hier geht es:
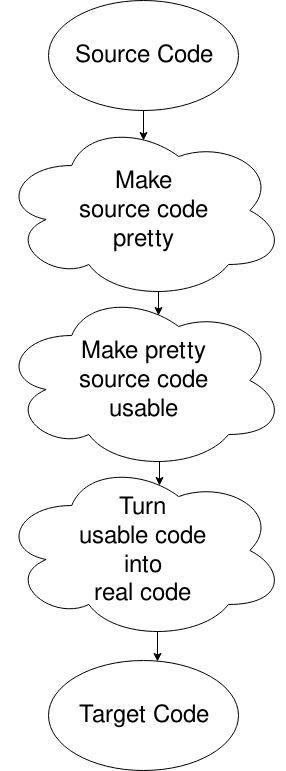
Hoppla, ich habe das falsche Diagramm ausgewählt, aber das reicht. Grundsätzlich erhalten Sie die Quelldatei, Sie legen sie in ein Format, das der Computer möchte (Entfernen von Leerzeichen und ähnlichem), ändern sie in etwas, in dem sich der Computer gut bewegen kann, und generieren Sie dann den Code daraus. Da ist noch mehr drin. Das ist für ein anderes Mal oder für Ihre eigene Forschung, wenn Ihre Neugier Sie tötet.,
Lexikalische Analyse
AKA „Making source code pretty“
Betrachten Sie die folgende vollständig erfundene Sprache, die im Grunde nur ein Taschenrechner mit Semikolons ist:
// source.ect 3 + 3.2; 5.0 / 1.9; 6 * 2;Der Computer benötigt nicht alles. Räume sind nur für unsere kleinen Köpfe. Und neue Linien? Niemand braucht diese. Der Computer verwandelt diesen Code, den Sie sehen, in einen Strom von Token, die er anstelle der Quelldatei verwenden kann., Grundsätzlich weiß es, dass 3 eine Ganzzahl ist, 3.2 ein Float ist und + mit diesen beiden Werten arbeitet. Das ist alles, was der Computer wirklich braucht, um auszukommen. Es ist die Aufgabe des lexikalischen Analysators, diese Token anstelle eines Quellprogramms bereitzustellen.
Wie es das macht, ist wirklich ganz einfach: Geben Sie dem Lexer (eine weniger anspruchsvoll klingende Art, lexikalischen Analysator zu sagen) einige Dinge zu erwarten, und sagen Sie ihm dann, was zu tun ist, wenn er dieses Zeug sieht. Diese werden Regeln genannt., Hier ist ein Beispiel:
int cout << "I see an integer!" << endl;Wenn ein int durch den Lexer kommt und diese Regel ausgeführt wird, werden Sie mit einem ziemlich offensichtlichen „Ich sehe eine ganze Zahl!“ Ausrufezeichen. So werden wir den Lexer nicht verwenden, aber es ist nützlich zu sehen, dass die Codeausführung willkürlich ist: Es gibt keine Regeln, dass Sie ein Objekt erstellen und zurückgeben müssen, es ist nur normaler alter Code. Kann sogar mehr als eine Linie verwenden, indem Sie sie mit Klammern umgeben.,
Übrigens werden wir etwas namens FLEX für unser Lexing verwenden. Es macht die Dinge ziemlich einfach, aber nichts hindert Sie daran, nur ein Programm zu erstellen, das dies selbst tut.
Um zu verstehen, wie wir flex verwenden werden, schauen Sie sich dieses Beispiel an:
Dies führt ein paar neue Konzepte ein, also gehen wir über sie:
%% wird verwendet, um Abschnitte des zu trennen .lex-Datei. Der erste Abschnitt sind Deklarationen-im Grunde Variablen, um den Lexer lesbarer zu machen., Es ist auch, wo Sie importieren, umgeben von %{ und %}.
Zweiter Teil sind die Regeln, die wir vorher gesehen haben. Diese sind im Grunde ein großes if else if block. Es wird die Zeile mit der längsten Übereinstimmung ausgeführt. Selbst wenn Sie die Reihenfolge von float und int ändern, stimmen die Floats weiterhin überein, da die Übereinstimmung von 3 Zeichen von 3.2 mehr als 1 Zeichen von 3., Beachten Sie, dass, wenn keine dieser Regeln übereinstimmt, es geht auf die Standardregel, Drucken Sie einfach das Zeichen auf Standard aus. Sie können dann yytext, um auf das zu verweisen, was mit dieser Regel übereinstimmt.
Der dritte Teil ist der Code, bei dem es sich einfach um C – oder C++ – Quellcode handelt, der bei der Ausführung ausgeführt wird. yylex(); ist ein Funktionsaufruf, der den Lexer ausführt. Sie können es auch dazu bringen, Eingaben aus einer Datei zu lesen,standardmäßig liest es jedoch aus Standardeingaben.
Angenommen, Sie haben diese beiden Dateien als source.ect und scanner.lexerstellt., Wir können ein C++ – Programm mit dem Befehl flex erstellen (vorausgesetzt, Sie haben flex installiert), dann kompilieren Sie das und geben Sie unseren Quellcode ein, um unsere großartigen Druckanweisungen zu erreichen. Lass uns das in die Tat umsetzen!
Hey, cool! Sie schreiben nur C++ – Code, der den Eingaben an Regeln entspricht, um etwas zu tun.
Wie verwenden Compiler das? Im Allgemeinen gibt jede Regel etwas zurück, anstatt etwas zu drucken – ein Token! Diese Token können im nächsten Teil des Compilers definiert werden…,
Syntax Analyzer
AKA „Making pretty source code nutzbar“
Es ist Zeit, Spaß zu haben! Sobald wir hier sind, beginnen wir, die Struktur des Programms zu definieren. Der Parser erhält nur einen Token-Stream und muss Elemente in diesem Stream abgleichen, damit der Quellcode eine verwendbare Struktur hat. Um dies zu tun, verwendet es Grammatiken, das Ding, das Sie wahrscheinlich in einer Theorieklasse gesehen haben oder von Ihrem seltsamen Freund gehört haben. Sie sind unglaublich mächtig, und es gibt so viel zu tun, aber ich werde nur geben, was Sie für unseren sorta dummen Parser wissen müssen.,
Grundsätzlich stimmen Grammatiken Nicht-Terminal-Symbolen mit einer Kombination von Terminal – und Nicht-Terminal-Symbolen überein. Terminals sind Blätter des Baumes; Nicht-Terminals haben Kinder. Mach dir keine Sorgen, wenn das keinen Sinn ergibt, wird der Code wahrscheinlich verständlicher sein.
Wir werden einen Parser-Generator namens Bison verwenden. Dieses Mal werde ich die Datei zu Erklärungszwecken in Abschnitte aufteilen. Zuerst die Deklarationen:
Der erste Teil sollte vertraut aussehen: Wir importieren Dinge, die wir verwenden möchten. Danach wird es etwas kniffliger.,
Die Vereinigung ist eine Zuordnung eines „echten“ C++ – Typs zu dem, was wir in diesem Programm nennen werden. Wenn wir also intVal, können Sie dies in Ihrem Kopf durch int ersetzen, und wenn wir floatVal, können Sie dies in Ihrem Kopf durch float. Du wirst später sehen warum.
als Nächstes kommen wir zu den Symbolen. Sie können diese in Ihrem Kopf als Terminals und Nicht-Terminals aufteilen, wie bei den Grammatiken, über die wir zuvor gesprochen haben. Großbuchstaben bedeuten Terminals, damit sie nicht weiter expandieren., Kleinbuchstaben bedeutet Nicht-Terminals, so dass sie weiter zu erweitern. Das ist nur Konvention.
Jede Deklaration (beginnend mit %) deklariert ein Symbol. Zuerst sehen wir, dass wir mit einem Nicht-Terminal beginnen program. Dann definieren wir einige Token. Die Klammern <> definieren den Rückgabetyp: Das Terminal INTEGER_LITERAL gibt also eine intVal. SEMI terminal gibt nichts zurück., Ähnliches kann bei Nicht-Terminals mit type, wie bei der Definition von exp als Nicht-Terminal, das a floatVal.
Endlich haben wir Vorrang. Wir kennen PEMDAS oder ein anderes Akronym, das Sie möglicherweise gelernt haben und das Ihnen einige einfache Vorrang-Regeln gibt: Multiplikation kommt vor Addition usw. Jetzt erklären wir das hier auf seltsame Weise. Erstens bedeutet niedriger in der Liste höhere Priorität. Zweitens fragen Sie sich vielleicht, was die left bedeutet., Das ist Assoziativität: Wenn wir a op b op c haben, gehen a und b zusammen oder vielleicht b und c? Die meisten unserer Operatoren machen das erstere, wobei a und b zuerst zusammengehen: das nennt man linke Assoziativität. Einige Operatoren, wie die Exponentiation, machen das Gegenteil: a^b^c erwartet, dass Sie dann a^(b^c). Damit werden wir uns jedoch nicht befassen., Schauen Sie sich die Bison-Seite an, wenn Sie mehr Details wünschen.
Okay, ich habe dich wahrscheinlich genug mit Deklarationen gelangweilt, hier sind die Grammatikregeln:
Dies ist die Grammatik, über die wir vorher gesprochen haben. Wenn Sie mit Grammatiken nicht vertraut sind, ist es ziemlich einfach: Die linke Seite kann sich in eines der Dinge auf der rechten Seite verwandeln, getrennt mit | (logisch or). Wenn es mehrere Wege gehen kann, ist das ein Nein-Nein, wir nennen das eine mehrdeutige Grammatik., Dies ist aufgrund unserer Prioritätsdeklarationen nicht mehrdeutig – wenn wir es so ändern, dass plus nicht mehr assoziativ bleibt, sondern stattdessen als token wie SEMI, sehen wir, dass wir einen shift/Reduce-Konflikt erhalten. Willst du mehr wissen? Schauen Sie nach, wie Bison funktioniert, Hinweis, es verwendet einen LR-Parsing-Algorithmus.
Okay, also kann exp einer dieser Fälle werden: eine INTEGER_LITERAL, eine FLOAT_LITERAL usw. Beachten Sie, dass es auch rekursiv ist, sodass exp zu zwei expwerden kann., Auf diese Weise können wir komplexe Ausdrücke wie 1 + 2 / 3 * 5. Jede exp gibt einen Float-Typ zurück.
Was sich in den Klammern befindet, ist dasselbe wie beim Lexer: beliebiger C++ – Code, aber mit seltsamerem syntaktischem Zucker. In diesem Fall werden spezielle Variablen mit $vorangestellt. Die Variable $$ wird grundsätzlich zurückgegeben. $1 wird vom ersten Argument zurückgegeben, $2 vom zweiten usw., Mit „argument“ meine ich Teile der Grammatikregel: Die Regel exp PLUS exp hat also Argument 1 exp, Argument 2 PLUS und Argument 3 exp. In unserer Codeausführung fügen wir dem dritten das Ergebnis des ersten Ausdrucks hinzu.
Schließlich, sobald es wieder auf die program nicht-Terminal, es wird das Ergebnis der Anweisung drucken. Ein Programm ist in diesem Fall eine Reihe von Anweisungen, wobei Anweisungen ein Ausdruck sind, gefolgt von einem Semikolon.
Jetzt schreiben wir den Codeteil., Dies ist, was tatsächlich ausgeführt wird, wenn wir durch den Parser gehen:
Okay, das fängt an, interessant zu werden. Unsere Hauptfunktion liest jetzt aus einer Datei, die vom ersten Argument anstelle von standard in bereitgestellt wird, und wir haben einen Fehlercode hinzugefügt. Es ist ziemlich selbsterklärend und Kommentare erklären gut, was los ist, also überlasse ich es dem Leser als Übung, dies herauszufinden. Alles, was Sie wissen müssen, ist, dass wir jetzt zum Lexer zurückkehren, um die Token dem Parser zur Verfügung zu stellen! Hier ist unser neuer Lexer:
Hey, das ist jetzt tatsächlich kleiner!, Was wir sehen, ist, dass wir, anstatt zu drucken, Terminalsymbole zurückgeben. Einige davon, wie Ints und Floats, setzen wir zuerst den Wert, bevor wir fortfahren (yylval ist der Rückgabewert des Terminalsymbols). Abgesehen davon gibt es dem Parser nur einen Stream von Terminal-Token, die nach eigenem Ermessen verwendet werden können.
Cool, können führen Sie es dann!
Los geht ‚ s – unser Parser druckt die richtigen Werte! Aber das ist nicht wirklich ein Compiler, es läuft nur C++ – Code, der ausführt, was wir wollen. Um einen Compiler zu erstellen, möchten wir dies in Maschinencode umwandeln., Dazu müssen wir noch ein bisschen mehr hinzufügen…
Bis zum Nächsten Mal…
ich bin zu realisieren, dass dies nun der post wird viel länger, als ich mir vorgestellt habe, also dachte ich, ich würde dieses hier. Wir haben im Grunde einen funktionierenden Lexer und Parser, also ist es ein guter Haltepunkt.
Ich habe den Quellcode auf meinem Github abgelegt, wenn Sie neugierig sind, das Endprodukt zu sehen. Wenn mehr Beiträge veröffentlicht werden, wird in diesem Repo mehr Aktivität angezeigt.,
Mit unserem Lexer und Parser können wir jetzt eine Zwischendarstellung unseres Codes generieren, die schließlich in echten Maschinencode konvertiert werden kann, und ich zeige Ihnen genau, wie es geht.
Zusätzliche Ressourcen
Wenn Sie weitere Informationen zu hier behandelten Themen wünschen, habe ich einige Dinge verknüpft, um loszulegen. Ich ging direkt über eine Menge, so ist dies meine Chance, Ihnen zu zeigen, wie in diese Themen zu tauchen.
Oh, übrigens, wenn Sie meine Phasen eines Compilers nicht mochten, hier ist ein tatsächliches Diagramm. Ich habe immer noch die Symboltabelle und den Fehlerhandler weggelassen., Beachten Sie auch, dass sich viele Diagramme davon unterscheiden, aber dies zeigt am besten, worum es uns geht.

Schreibe einen Kommentar