Wir gehen nun auf das frühere Beispiel zurück, 100 Personen (darunter 40 schwangere Frauen und die restlichen 60 sind keine schwangeren Frauen und Männer mit einem fetten Bauch) als schwanger oder nicht schwanger zu klassifizieren. Von 40 schwangeren Frauen werden 30 schwangere Frauen korrekt klassifiziert und die restlichen 10 schwangeren Frauen werden vom maschinellen Lernalgorithmus als nicht schwanger klassifiziert. Auf der anderen Seite werden von 60 Personen in der Kategorie nicht schwanger 55 als nicht schwanger und die restlichen 5 als schwanger eingestuft.,
In diesem Fall, TN = 55, FP = 5 FN = 10, TP = 30. Die Verwirrungsmatrix ist wie folgt.
Bild 6: Confusion matrix für die schwangere vs nicht Schwanger Klassifizierung.
Was ist die Genauigkeit des Machine Learning-Modells für diese Klassifizierungsaufgabe?,
Genauigkeit repräsentiert die Anzahl der korrekt klassifizierten Dateninstanzen über die Gesamtzahl der dateninstanzen.
In diesem Beispiel Genauigkeit = (55 + 30)/(55 + 5 + 30 + 10 ) = 0.85 und in Prozent beträgt die Genauigkeit 85%.
Ist Genauigkeit das beste Maß?
Genauigkeit ist möglicherweise kein gutes Maß, wenn der Datensatz nicht ausgeglichen ist (sowohl negative als auch positive Klassen haben unterschiedliche Anzahl von Dateninstanzen)., Wir werden dies mit einem Beispiel erklären.
Betrachten Sie das folgende Szenario: Es gibt 90 Menschen, die gesund sind (negativ) und 10 Menschen, die eine Krankheit haben (positiv). Nehmen wir an, unser Modell für maschinelles Lernen klassifizierte die 90 Menschen perfekt als gesund, klassifizierte aber auch die ungesunden Menschen als gesund. Was wird in diesem Szenario passieren? Lassen Sie uns die Verwirrungsmatrix sehen und die Genauigkeit herausfinden?
In diesem Beispiel TN = 90, FP = 0, FN = 10 und TP = 0. Die Verwirrungsmatrix ist wie folgt.,
Bild 7: Confusion-matrix für gesunde vs ungesunde Menschen classification task.
Genauigkeit wird in diesem Fall sein (90 + 0)/(100) = 0.9 und in Prozent beträgt die Genauigkeit 90 %.
gibt es etwas fischig?
Die Genauigkeit beträgt in diesem Fall 90 % , aber dieses Modell ist sehr schlecht, da alle 10 Personen, die ungesund sind, als gesund eingestuft werden., In diesem Beispiel versuchen wir zu sagen, dass Genauigkeit keine gute Metrik ist, wenn der Datensatz unausgeglichen ist. Die Verwendung von Genauigkeit in solchen Szenarien kann zu einer irreführenden Interpretation der Ergebnisse führen.
Jetzt gehen wir weiter, um eine andere Metrik für die Klassifizierung herauszufinden. Wieder kehren wir zum Beispiel der Schwangerschaftsklassifizierung zurück.
Jetzt finden wir die Genauigkeit (positiver Vorhersagewert) bei der Klassifizierung der Dateninstanzen., Präzision ist wie folgt definiert:
Was bedeutet Präzision bedeuten?
Die Genauigkeit sollte idealerweise 1 (hoch) für einen guten Klassifikator sein. Die Genauigkeit wird nur dann zu 1, wenn Zähler und Nenner gleich sind, dh TP = TP +FP, dies bedeutet auch, dass FP Null ist. Wenn FP zunimmt, wird der Wert des Nenners größer als der Zähler und der Präzisionswert nimmt ab (was wir nicht wollen).
Also im Schwangerschaftsbeispiel Präzision = 30/(30+ 5) = 0.,857
Jetzt werden wir eine weitere wichtige Metrik namens Recall einführen. Der Rückruf wird auch als Empfindlichkeit oder wahr positive Rate bezeichnet und ist wie folgt definiert:
Der Rückruf sollte idealerweise 1 (hoch) für einen guten Klassifikator. Der Rückruf wird nur dann zu 1, wenn Zähler und Nenner gleich sind, dh TP = TP +FN, dies bedeutet auch, dass FN Null ist., Wenn FN zunimmt, wird der Wert des Nenners größer als der Zähler und der Rückrufwert nimmt ab (was wir nicht wollen).
Lassen Sie uns also im Schwangerschaftsbeispiel sehen, was der Rückruf sein wird.
Rückruf = 30/(30+ 10) = 0.75
Idealerweise möchten wir also in einem guten Klassifikator, dass sowohl Präzision als auch Rückruf eins sind, was auch bedeutet, dass FP und FN Null sind. Daher benötigen wir eine Metrik, die sowohl Präzision als auch Rückruf berücksichtigt., F1-score ist eine Metrik, die sowohl die Genauigkeit als auch den Rückruf berücksichtigt und wie folgt definiert ist:
F1 Score wird nur dann zu 1, wenn Präzision und Rückruf beide 1 sind. F1 Score wird nur dann hoch, wenn Präzision und Rückruf hoch sind. F1 Score ist das harmonische Mittel von Präzision und Rückruf und ist ein besseres Maß als Genauigkeit.
In der Schwangerschaft Beispiel, F1-Score = 2* ( 0.857 * 0.75)/(0.857 + 0.75) = 0.799.,
Leseliste
Im Folgenden finden Sie einen interessanten Artikel über die gemeinsame binäre Klassifikationsmetrik von neptune.ai. Der Link zum Artikel ist hier verfügbar: https://neptune.ai/blog/f1-score-accuracy-roc-auc-pr-auc



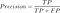


Schreibe einen Kommentar